Exam Details
Exam Code
:E20-007Exam Name
:Data Science and Big Data AnalyticsCertification
:EMC CertificationsVendor
:EMCTotal Questions
:198 Q&AsLast Updated
:Mar 30, 2025
EMC EMC Certifications E20-007 Questions & Answers
-
Question 151:
When is a Wilcoxon Rank-Sum test used?
A. When an assumption about the distribution of the populations cannot be made
B. When the data can be easily sorted
C. When the populations represent the sums of other values
D. When the data cannot be easily sorted
-
Question 152:
Consider these itemsets:
(hat, scarf, coat)
(hat, scarf, coat, gloves)
(hat, scarf, gloves)
(hat, gloves)
(scarf, coat, gloves)
What is the confidence of the rule (hat, scarf) -> gloves?
A. 66%
B. 40%
C. 50%
D. 60%
-
Question 153:
Refer to the exhibit.
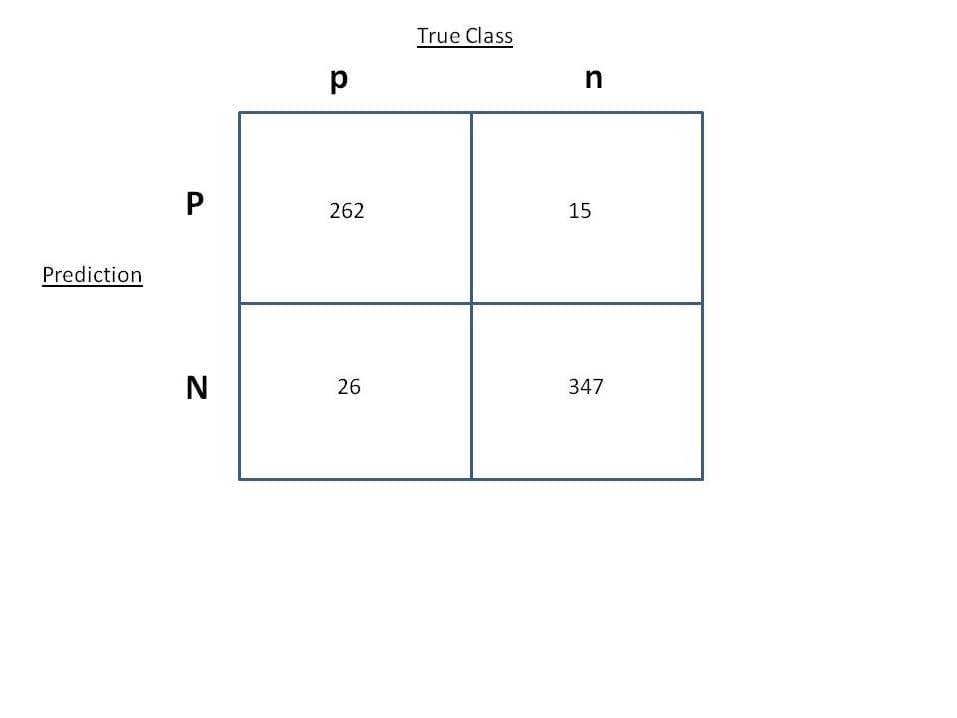
You have scored your Naive bayesian classifier model on a hold out test data for cross validation and
determined the way the samples scored and tabulated them as shown in the exhibit.
What are the the False Positive Rate (FPR) and the False Negative Rate (FNR) of the model?
A. FPR = 15/262 FNR = 26/288
B. FPR = 26/288 FNR = 15/262
C. FPR = 262/15 FNR = 288/26
D. FPR = 288/26 FNR = 262/15
-
Question 154:
You have been assigned to run a linear regression model for each of 5, 000 distinct districts, and all the data is currently stored in a PostgreSQL database. Which tool/library would you use to produce these models with the least effort?
A. MADlib
B. Mahout
C. R
D. HBase
-
Question 155:
While having a discussion with your colleague, this person mentions that they want to perform K-means clustering on text file data stored in HDFS.
Which tool would you recommend to this colleague?
A. Mahout
B. HBase
C. Scribe
D. Sqoop
-
Question 156:
You are studying the behavior of a population and are provided with multi-dimensional data at the individual level. You have identified four specific individuals who are valuable to your study. You would like to find all users who are most similar to each individual.
Which algorithm is most appropriate for this study?
A. K-means clustering
B. Linear regression
C. Association rules
D. Decision trees
-
Question 157:
Refer to the exhibit.
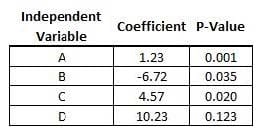
After analyzing a dataset, you report findings to your team:
1.
Variables A and C are significantly and positively impacting the dependent variable.
2.
Variable B is significantly and negatively impacting the dependent variable.
3.
Variable D is not significantly impacting the dependent variable.
After seeing your findings, the majority of your team agreed that variable B should be positively impacting
the dependent variable.
What is a possible reason the coefficient for variable B was negative and not positive?
A. Variable B is interacting with another variable due to correlated inputs
B. Variable B needs a quadratic transformation due to its relationship to the dependent variable
C. The information gain from variable B is already provided by another variable
D. Variable B needs a logarithmic transformation due to its relationship to the dependent variable
-
Question 158:
Refer to the exhibit.
You ran a linear regression, and the final output is seen in the exhibit.
Based only on the information in the exhibit and an acceptable confidence level of 95%, how would you interpret the interaction of variable D with the dependent variable?
A. In this model, Variable D is not significantly interacting with the dependent variable
B. For every 1 unit increase in variable D, holding all other variables constant, we can expect the dependent variable to increase by 10.23 units
C. For every 1 unit increase in variable D, holding all other variables constant, we can expect the dependent variable to be multiplied by 10.23 units
D. Variable D is more significant than variables A, B, and C.
-
Question 159:
You submit a MapReduce job to a Hadoop cluster. However, you notice that although the job was
successfully submitted, it is not completing.
What should be done to identify the issue?
A. Ensure TaskTracker is running
B. Ensure JobTracker is running
C. Ensure NameNode is running
D. Ensure DataNode is running
-
Question 160:
You have two tables of customers in your database. Customers in cust_table_1 were sent an e-mail promotion last year, and customers in cust_table_2 received a newsletter last year. Customers can only be entered in once per table. You want to create a table that includes all customers, and any of the communications they received last year. Which type of join would you use for this table?
A. Full outer join
B. Inner join
C. Left outer join
D. Cross join
Related Exams:
D-GAI-F-01
Dell GenAI Foundations AchievementD-MSS-DS-23
Dell Midrange Storage Solutions Design 2023D-OME-OE-A-24
Dell OpenManage Operate AchievementD-PDD-DY-23
Dell PowerProtect DD Deploy 2023D-PE-OE-23
Dell PowerEdge Operate 2023D-PEXE-IN-A-00
Dell PowerEdge XE9680 and XE8640 InstallD-PSC-MN-01
Dell GenAI Foundations AchievementD-PST-MN-A-24
Dell PowerStore Maintenance AchievementD-PWF-DS-23
Dell PowerFlex Design 2023D-RP-DY-A-24
Dell RecoverPoint Deploy Achievement
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only EMC exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your E20-007 exam preparations and EMC certification application, do not hesitate to visit our Vcedump.com to find your solutions here.