Exam Details
Exam Code
:VCP550Exam Name
:VMware Certified Professional - Data Center VirtualizationCertification
:VMware CertificationsVendor
:VMwareTotal Questions
:267 Q&AsLast Updated
:Dec 16, 2024
VMware VMware Certifications VCP550 Questions & Answers
-
Question 151:
An administrator needs to configure an alarm that notifies administrators if an application is impacted by overcommitment of memory resources. The environment consists of 100 virtual machines running on 5 ESXi hosts that are configured in a fully automated HA/DRS cluster. The cluster is configured with a parent resource pool and Production and Development child pools.
Where should the administrator set the alarm to meet the requirement?
A. On each virtual machine
B. On each host
C. On the Production resource pool
D. On the cluster
-
Question 152:
A vSphere administrator receives a request to capture the state of a virtual machine six times a day. Which procedure will satisfy the requirement with the least amount of administrator intervention?
A. Use the vSphere web client to configure a scheduled task to take a snapshot every four hours.
B. Use the vSphere web client to configure a scheduled workflow to take a snapshot every four hours.
C. Use the vSphere web client to manually initiate a snapshot of the virtual machine every four hours.
D. Use the vSphere web client to schedule an automated snapshot every four hours using Snapshot Manager.
-
Question 153:
What action should an administrator take to store ESXi 5.x host system logs centrally?
A. Configure vCenter Server to automatically export log files to a syslog server at regular intervals.
B. Configure vCenter Server to send all log information to a syslog server.
C. Configure each ESXi host to send all log information to a syslog server.
D. Configure the syslog server to import log files from each ESXi host at regular intervals.
-
Question 154:
An organization has a HA/DRS cluster containing a mixture of ESXi 4.1 and 5.5 hosts in the cluster. An ESXi 5.5 host has failed and HA attempted but failed to restart the virtual machines on another host. HA admission control is disabled. What condition could result in this behavior?
A. A virtual machine has an incompatible hardware version
B. Insufficient resources exist on the remaining ESXi hosts
C. vMotion migration is not supported between ESXi 5.5 and 4.1 hosts
D. HA failover is not supported between ESXi 5.5 and 4.1 hosts
-
Question 155:
Which condition will cause a HA/DRS cluster to display a yellow health indicator?
A. There are insufficient resources to satisfy the cluster's requirements.
B. A virtual machine has failed and cannot be restarted in the cluster.
C. Virtual machine I/O activity in the cluster has reached or exceeded a critical level.
D. One or more hosts in the cluster has entered maintenance mode.
-
Question 156:
A vSphere administrator finds a HA/DRS cluster status has turned RED indicating a degraded state.
What is the likely reason for the indication?
A. The cluster enabled for HA has lost resources and is unable to fulfill its failover requirements.
B. The cluster does not have enough resources to satisfy the reservations of all resource pools and virtual machines.
C. Incompatible CPU generations between hosts are preventing DRS migrations.
D. The cluster is currently electing a Master host and is unavailable to perform HA functions.
-
Question 157:
-- Exhibit -
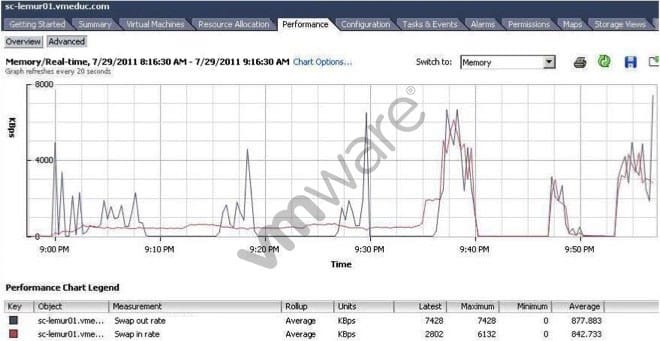
-- Exhibit -What is indicated by the performance chart shown?
A. Guest memory is overcommitted.
B. Host memory is overcommitted.
C. Host is I/O constrained.
D. Guest is I/O constrained.
-
Question 158:
An administrator needs to use performance information from Windows virtual machines to better understand their effect on the vSphere 5.x hosts on which they run. What must the administrator do to collect this information?
A. Install VMware Tools with the PERFMON counters enabled in the Advanced option of the installer.
B. Install VMware Tools. Add counters in the PERFMON utility.
C. Install VMware Tools. Edit the VMware Tools settings to enable the VM-specific counters.
D. Install VMware Tools. Install the PERFMON plug-in for VMware Tools.
-
Question 159:
A VMFS5 datastore shows several errors, which suggests file system corruption. Which tool could a vSphere administrator use to check the VMFS file system?
A. vSphere On-disk Metadata Analyzer (VOMA)
B. VMware Infrastructure Management Assistant (VIMA)
C. vSphere Storage APIs for Storage Awareness (VASA)
D. VMware vSphere Health Check Analyzer (VHCA)
-
Question 160:
A Windows Server 2008 virtual machine with the following configuration receives an Out of Space condition indicator:
The virtual machine uses thin provisioned virtual disks.
The VMFS5 datastore on which the virtual machine's files reside is on a thin provisioned LUN.
30% of the VMFS datastore content is no longer needed.
The storage array supports VASA and VAAI.
Which action should the vSphere administrator take to resolve the Out of Space problem without requesting additional space on the storage array?
A.
Delete unneeded files on the VMFS datastore and then use vmkfstools to reclaim deleted blocks.
B.
Delete unneeded files on the VMFS datastore, right-click the datastore in vSphere Web Client, and then select the Reclaim Deleted Blocks option.
C.
Delete some files from the guest OS and defrag its file system.
D.
Delete some files from the guest OS and use vmkfstools to reclaim the deleted blocks.
Related Exams:
1V0-21.20
Associate VMware Data Center Virtualization1V0-31.21
Associate VMware Cloud Management and Automation1V0-41.20
Associate VMware Network Virtualization1V0-61.21
Associate VMware Digital Workspace1V0-71.21
Associate VMware Application Modernization1V0-81.20
Associate VMware Security2V0-21.20
Professional VMware vSphere 7.x2V0-21.23
VMware vSphere 8.x Professional2V0-31.21
Professional VMware vRealize Automation 8.32V0-31.23
VMware Aria Automation 8.10 Professional
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only VMware exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your VCP550 exam preparations and VMware certification application, do not hesitate to visit our Vcedump.com to find your solutions here.