Microsoft Microsoft Certifications AI-900 Questions & Answers
Question 11:
DRAG DROP
Match the principles of responsible AI to appropriate requirements.
To answer, drag the appropriate principles from the column on the left to its requirement on the right. Each principle may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
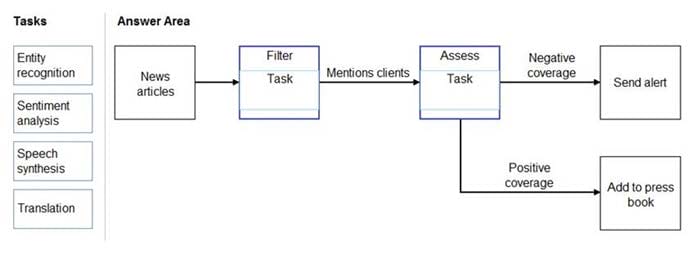
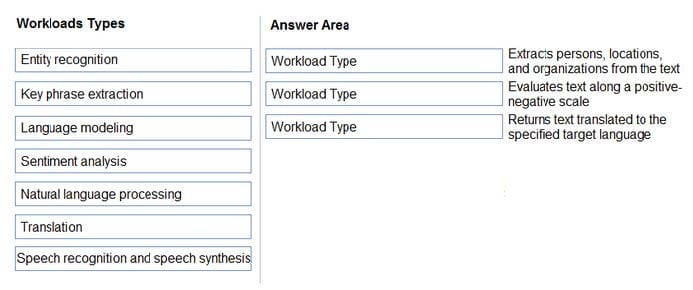
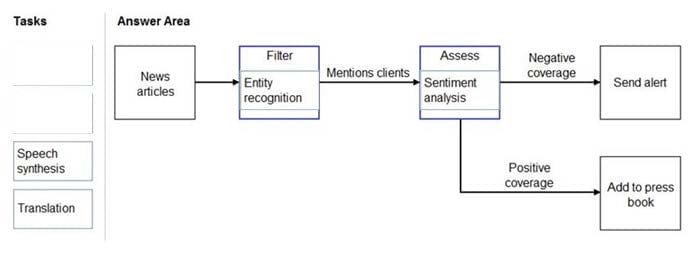
DRAG DROP You need to scan the news for articles about your customers and alert employees when there is a negative article. Positive articles must be added to a press book. Which natural language processing tasks should you use to complete the process? To answer, drag the appropriate tasks to the correct locations. Each task may be used once, more than once, or not at all. You may need to drag the split bar
between panes or scroll to view content. NOTE: Each correct selection is worth one point.
Select and Place:
Correct Answer:
Box 1: Entity recognition
the Named Entity Recognition module in Machine Learning Studio (classic), to identify the names of things, such as people, companies, or locations in a column of text.
Named entity recognition is an important area of research in machine learning and natural language processing (NLP), because it can be used to answer many real-world questions, such as:
Which companies were mentioned in a news article?
Does a tweet contain the name of a person? Does the tweet also provide his current location?
Were specified products mentioned in complaints or reviews?
Box 2: Sentiment Analysis
The Text Analytics API's Sentiment Analysis feature provides two ways for detecting positive and negative sentiment. If you send a Sentiment Analysis request, the API will return sentiment labels (such as "negative", "neutral" and "positive")
and confidence scores at the sentence and document-level.
Match the types of machine learning to the appropriate scenarios.
To answer, drag the appropriate machine learning type from the column on the left to its scenario on the right. Each machine learning type may be used once, more than once, or not at all.
NOTE: Each correct selection is worth one point.
Select and Place:
Correct Answer:
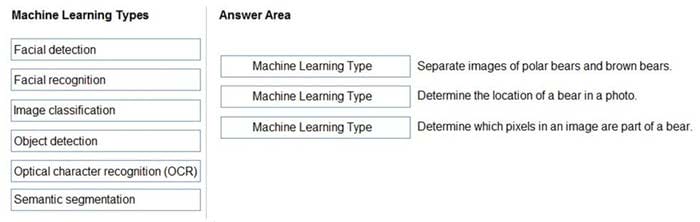
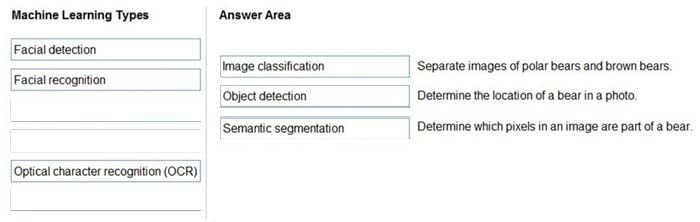
Box 1: Image classification
Image classification is a supervised learning problem: define a set of target classes (objects to identify in images), and train a model to recognize them using labeled example photos.
Box 2: Object detection
Object detection is a computer vision problem. While closely related to image classification, object detection performs image classification at a more granular scale. Object detection both locates and categorizes entities within images.
Box 3: Semantic Segmentation
Semantic segmentation achieves fine-grained inference by making dense predictions inferring labels for every pixel, so that each pixel is labeled with the class of its enclosing object ore region.
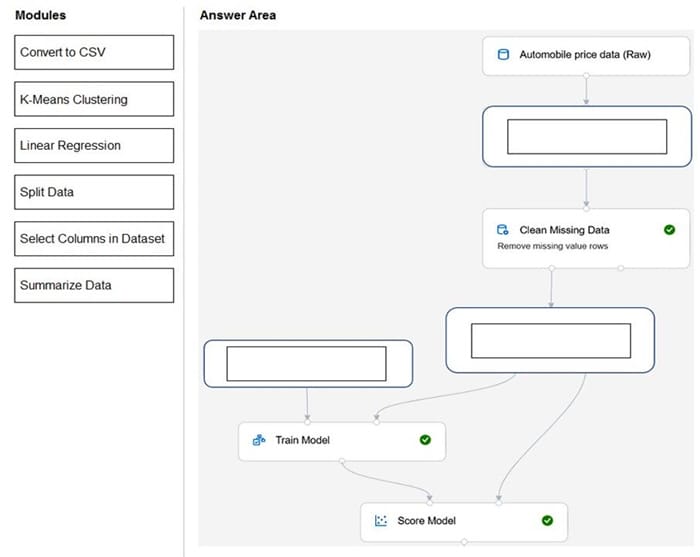
You need to use Azure Machine Learning designer to build a model that will predict automobile prices.
Which type of modules should you use to complete the model? To answer, drag the appropriate modules to the correct locations. Each module may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
Correct Answer:
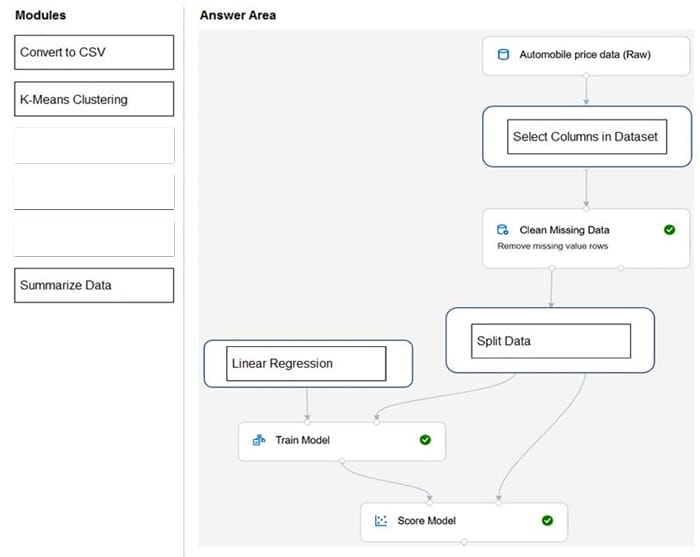
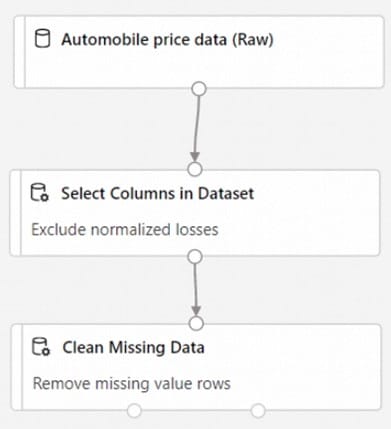
Box 1: Select Columns in Dataset
For Columns to be cleaned, choose the columns that contain the missing values you want to change. You can choose multiple columns, but you must use the same replacement method in all selected columns.
Example:
Box 2: Split data
Splitting data is a common task in machine learning. You will split your data into two separate datasets. One dataset will train the model and the other will test how well the model performed.
Box 3: Linear regression
Because you want to predict price, which is a number, you can use a regression algorithm. For this example, you use a linear regression model.
Question 15:
DRAG DROP
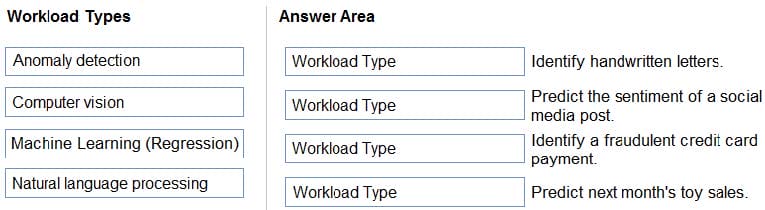
Match the types of AI workloads to the appropriate scenarios.
To answer, drag the appropriate workload type from the column on the left to its scenario on the right. Each workload type may be used once, more than once, or not at all.
NOTE: Each correct selection is worth one point.
Select and Place:
Correct Answer:
Box 1: Computer vision
Optical character recognition (OCR), included in Computer Vision, allows you to extract printed or handwritten text from images, such as photos of street signs and products, as well as from documents — invoices, bills, financial reports,
articles, and more
Box 2: Natural language processing
Choose a natural language processing service for sentiment analysis, topic and language detection, key phrase extraction, and document categorization.
Box 3: Anomaly detection
Box 4: Machine Learning (Clustering)
Clustering is the task of dividing the population or data points into a number of groups such that data points in the same groups are more similar to other data points in the same group and dissimilar to the data points in other groups. It is
basically a collection of objects on the basis of similarity and dissimilarity between them.
You plan to apply Text Analytics API features to a technical support ticketing system.
Match the Text Analytics API features to the appropriate natural language processing scenarios.
To answer, drag the appropriate feature from the column on the left to its scenario on the right. Each feature may be used once, more than once, or not at all.
NOTE: Each correct selection is worth one point.
Select and Place:
Correct Answer:
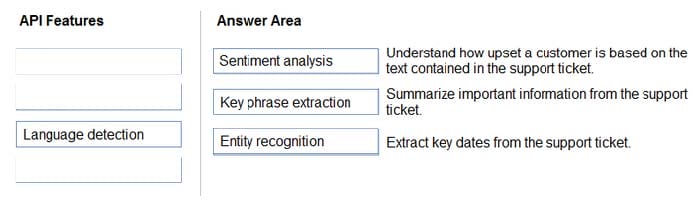
Box1: Sentiment analysis
Sentiment Analysis is the process of determining whether a piece of writing is positive, negative or neutral.
Box 2: Broad entity extraction
Broad entity extraction: Identify important concepts in text, including key
Key phrase extraction/ Broad entity extraction: Identify important concepts in text, including key phrases and named entities such as people, places, and organizations.
Box 3: Entity Recognition
Named Entity Recognition: Identify and categorize entities in your text as people, places, organizations, date/time, quantities, percentages, currencies, and more. Well-known entities are also recognized and linked to more information on the
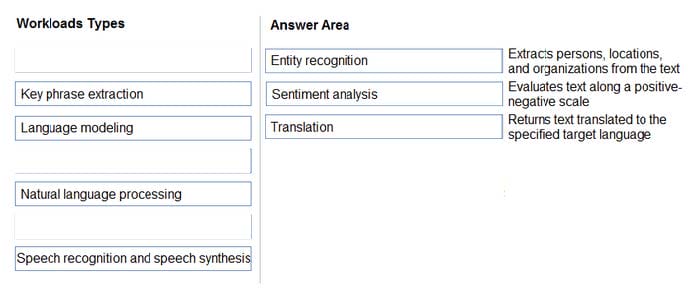
Match the types of natural languages processing workloads to the appropriate scenarios.
To answer, drag the appropriate workload type from the column on the left to its scenario on the right. Each workload type may be used once, more than once, or not at all.
NOTE: Each correct selection is worth one point.
Select and Place:
Correct Answer:
Box 1: Entity recognition
Classify a broad range of entities in text, such as people, places, organisations, date/time and percentages, using named entity recognition. Whereas:- Get a list of relevant phrases that best describe the subject of each record using key
phrase extraction.
Box 2: Sentiment analysis
Sentiment Analysis is the process of determining whether a piece of writing is positive, negative or neutral.
Box 3: Translation
Using Microsoft's Translator text API
This versatile API from Microsoft can be used for the following:
Translate text from one language to another.
Transliterate text from one script to another.
Detecting language of the input text.
Find alternate translations to specific text.
Determine the sentence length.
Incorrect Answers:
Not Natural language processing (NLP), which is used for tasks such as sentiment analysis, topic detection, language detection, key phrase extraction, and document categorization.
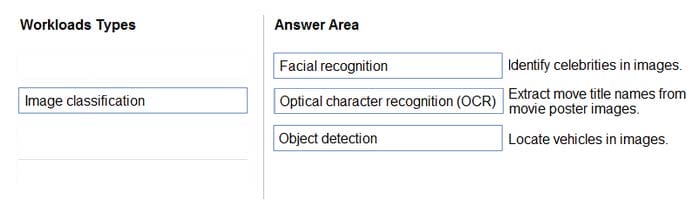
Match the types of computer vision to the appropriate scenarios.
To answer, drag the appropriate workload type from the column on the left to its scenario on the right. Each workload type may be used once, more than once, or not at all.
NOTE: Each correct selection is worth one point.
Select and Place:
Correct Answer:
Box 1: Facial recognition Face detection that perceives faces and attributes in an image; person identification that matches an individual in your private repository of up to 1 million people; perceived emotion recognition that detects a range of facial expressions like happiness, contempt, neutrality, and fear; and recognition and grouping of similar faces in images.
Box 2: OCR
Box 3: Objection detection Object detection is similar to tagging, but the API returns the bounding box coordinates (in pixels) for each object found. For example, if an image contains a dog, cat and person, the Detect operation will list those objects together with their coordinates in the image. You can use this functionality to process the relationships between the objects in an image. It also lets you determine whether there are multiple instances of the same tag in an image.
The Detect API applies tags based on the objects or living things identified in the image. There is currently no formal relationship between the tagging taxonomy and the object detection taxonomy. At a conceptual level, the Detect API only finds objects and living things, while the Tag API can also include contextual terms like "indoor", which can't be localized with bounding boxes.
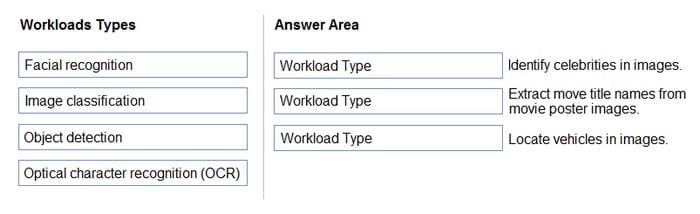
Match the facial recognition tasks to the appropriate questions.
To answer, drag the appropriate task from the column on the left to its question on the right. Each task may be used once, more than once, or not at all.
NOTE: Each correct selection is worth one point.
Select and Place:
Correct Answer:
Box 1: verification Face verification: Check the likelihood that two faces belong to the same person and receive a confidence score. Box 2: similarity
Box 3: Grouping Box 4: identification Face detection: Detect one or more human faces along with attributes such as: age, emotion, pose, smile, and facial hair, including 27 landmarks for each face in the image.
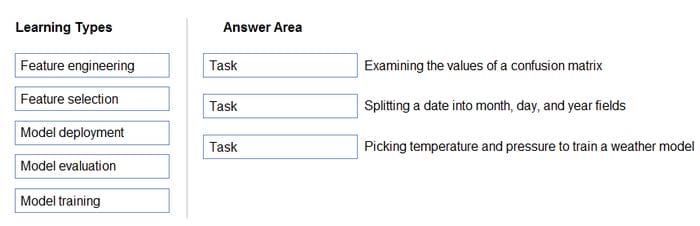
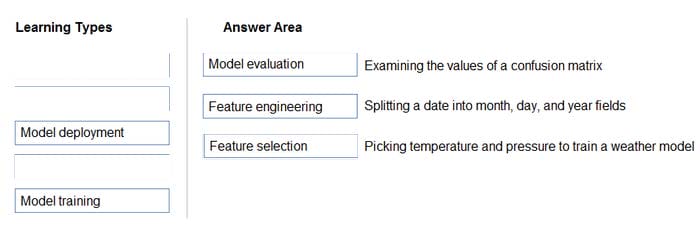
Match the machine learning tasks to the appropriate scenarios.
To answer, drag the appropriate task from the column on the left to its scenario on the right. Each task may be used once, more than once, or not at all.
NOTE: Each correct selection is worth one point.
Select and Place:
Correct Answer:
Box 1: Model evaluation
The Model evaluation module outputs a confusion matrix showing the number of true positives, false negatives, false positives, and true negatives, as well as ROC, Precision/Recall, and Lift curves.
Box 2: Feature engineering
Feature engineering is the process of using domain knowledge of the data to create features that help ML algorithms learn better. In Azure Machine Learning, scaling and normalization techniques are applied to facilitate feature engineering.
Collectively, these techniques and feature engineering are referred to as featurization.
Note: Often, features are created from raw data through a process of feature engineering. For example, a time stamp in itself might not be useful for modeling until the information is transformed into units of days, months, or categories that are
relevant to the problem, such as holiday versus working day.
Box 3: Feature selection
In machine learning and statistics, feature selection is the process of selecting a subset of relevant, useful features to use in building an analytical model. Feature selection helps narrow the field of data to the most valuable inputs. Narrowing
the field of data helps reduce noise and improve training performance.
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Microsoft exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your AI-900 exam preparations and Microsoft certification application, do not hesitate to visit our Vcedump.com to find your solutions here.