Exam Details
Exam Code
:DP-100Exam Name
:Designing and Implementing a Data Science Solution on AzureCertification
:Microsoft CertificationsVendor
:MicrosoftTotal Questions
:564 Q&AsLast Updated
:Jun 26, 2025
Microsoft Microsoft Certifications DP-100 Questions & Answers
-
Question 241:
You use the Azure Machine Learning Python SDK to define a pipeline that consists of multiple steps.
When you run the pipeline, you observe that some steps do not run. The cached output from a previous run is used instead.
You need to ensure that every step in the pipeline is run, even if the parameters and contents of the source directory have not changed since the previous run.
What are two possible ways to achieve this goal? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A. Use a PipelineData object that references a datastore other than the default datastore.
B. Set the regenerate_outputs property of the pipeline to True.
C. Set the allow_reuse property of each step in the pipeline to False.
D. Restart the compute cluster where the pipeline experiment is configured to run.
E. Set the outputs property of each step in the pipeline to True.
-
Question 242:
You use the following Python code in a notebook to deploy a model as a web service:
from azureml.core.webservice import AciWebservice
from azureml.core.model import InferenceConfig
inference_config = InferenceConfig(runtime='python', source_directory='model_files', entry_script='score.py', conda_file='env.yml')
deployment_config = AciWebservice.deploy_configuration(cpu_cores=1, memory_gb=1)
service = Model.deploy(ws, 'my-service', [model], inference_config, deployment_config)
service.wait_for_deployment(True)
The deployment fails.
You need to use the Python SDK in the notebook to determine the events that occurred during service deployment an initialization.
Which code segment should you use?
A. service.state
B. service.get_logs()
C. service.serialize()
D. service.environment
-
Question 243:
You plan to use a Data Science Virtual Machine (DSVM) with the open source deep learning frameworks Caffe2 and Theano. You need to select a pre configured DSVM to support the framework. Which of following should you create?
A. Data Science Virtual Machine for Linux (Ubuntu)
B. Data Science Virtual Machine for Windows 2012
C. Data Science Virtual Machine for Windows 2016
D. Data Science Virtual Machine for Linux (CentOS)
-
Question 244:
You plan to use a Python script to run an Azure Machine Learning experiment. The script creates a reference to the experiment run context, loads data from a file, identifies the set of unique values for the label column, and completes the experiment run:
from azureml.core import Run import pandas as pd run = Run.get_context() data = pd.read_csv('data.csv') label_vals = data['label'].unique() # Add code to record metrics here run.complete()
The experiment must record the unique labels in the data as metrics for the run that can be reviewed later.
You must add code to the script to record the unique label values as run metrics at the point indicated by the comment.
Solution: Replace the comment with the following code:
run.log_table('Label Values', label_vals)
Does the solution meet the goal?
A. Yes
B. No
-
Question 245:
You plan to use a Python script to run an Azure Machine Learning experiment. The script creates a reference to the experiment run context, loads data from a file, identifies the set of unique values for the label column, and completes the experiment run:
from azureml.core import Run import pandas as pd run = Run.get_context() data = pd.read_csv('data.csv') label_vals = data['label'].unique() # Add code to record metrics here run.complete()
The experiment must record the unique labels in the data as metrics for the run that can be reviewed later.
You must add code to the script to record the unique label values as run metrics at the point indicated by the comment.
Solution: Replace the comment with the following code:
for label_val in label_vals:
run.log('Label Values', label_val)
Does the solution meet the goal?
A. Yes
B. No
-
Question 246:
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while
others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You train and register a machine learning model.
You plan to deploy the model as a real-time web service. Applications must use key-based authentication to use the model.
You need to deploy the web service.
Solution:
Create an AciWebservice instance.
Set the value of the ssl_enabled property to True.
Deploy the model to the service.
Does the solution meet the goal?
A. Yes
B. No
-
Question 247:
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while
others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You train and register a machine learning model.
You plan to deploy the model as a real-time web service. Applications must use key-based authentication to use the model.
You need to deploy the web service.
Solution:
Create an AksWebservice instance.
Set the value of the auth_enabled property to True.
Deploy the model to the service.
Does the solution meet the goal?
A. Yes
B. No
-
Question 248:
You plan to use a Python script to run an Azure Machine Learning experiment. The script creates a reference to the experiment run context, loads data from a file, identifies the set of unique values for the label column, and completes the experiment run:
from azureml.core import Runimport pandas as pdrun = Run.get_context()data = pd.read_csv('data.csv')label_vals = data['label'].unique()# Add code to record metrics here run.complete()
The experiment must record the unique labels in the data as metrics for the run that can be reviewed later.
You must add code to the script to record the unique label values as run metrics at the point indicated by the comment.
Solution: Replace the comment with the following code:
run.upload_file('outputs/labels.csv', './data.csv')
Does the solution meet the goal?
A. Yes
B. No
-
Question 249:
You plan to use the Hyperdrive feature of Azure Machine Learning to determine the optimal hyperparameter values when training a model.
You must use Hyperdrive to try combinations of the following hyperparameter values:
1.
learning_rate: any value between 0.001 and 0.1
2.
batch_size: 16, 32, or 64
You need to configure the search space for the Hyperdrive experiment.
Which two parameter expressions should you use? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. a choice expression for learning_rate
B. a uniform expression for learning_rate
C. a normal expression for batch_size
D. a choice expression for batch_size
E. a uniform expression for batch_size
-
Question 250:
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You create an Azure Machine Learning service datastore in a workspace. The datastore contains the following files:
1.
/data/2018/Q1.csv
2.
/data/2018/Q2.csv
3.
/data/2018/Q3.csv
4.
/data/2018/Q4.csv
5.
/data/2019/Q1.csv
All files store data in the following format:
id,f1,f2,I 1,1,2,0 2,1,1,1 3,2,1,0 4,2,2,1
You run the following code:

You need to create a dataset named training_data and load the data from all files into a single data frame by using the following code:
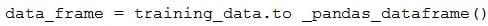
Solution: Run the following code:

Does the solution meet the goal?
A. Yes
B. No
Related Exams:
62-193
Technology Literacy for Educators70-243
Administering and Deploying System Center 2012 Configuration Manager70-355
Universal Windows Platform – App Data, Services, and Coding Patterns77-420
Excel 201377-427
Excel 2013 Expert Part One77-725
Word 2016 Core Document Creation, Collaboration and Communication77-726
Word 2016 Expert Creating Documents for Effective Communication77-727
Excel 2016 Core Data Analysis, Manipulation, and Presentation77-728
Excel 2016 Expert: Interpreting Data for Insights77-731
Outlook 2016 Core Communication, Collaboration and Email Skills
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Microsoft exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DP-100 exam preparations and Microsoft certification application, do not hesitate to visit our Vcedump.com to find your solutions here.