Exam Details
Exam Code
:DP-100Exam Name
:Designing and Implementing a Data Science Solution on AzureCertification
:Microsoft CertificationsVendor
:MicrosoftTotal Questions
:564 Q&AsLast Updated
:Mar 20, 2025
Microsoft Microsoft Certifications DP-100 Questions & Answers
-
Question 31:
You are evaluating a completed binary classification machine learning model.
You need to use the precision as the valuation metric.
Which visualization should you use?
A. Binary classification confusion matrix
B. box plot
C. Gradient descent
D. coefficient of determination
-
Question 32:
You use the Two-Class Neural Network module in Azure Machine Learning Studio to build a binary classification model. You use the Tune Model Hyperparameters module to tune accuracy for the model.
You need to select the hyperparameters that should be tuned using the Tune Model Hyperparameters module.
Which two hyperparameters should you use? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Number of hidden nodes
B. Learning Rate
C. The type of the normalizer
D. Number of learning iterations
E. Hidden layer specification
-
Question 33:
You are implementing hyperparameter tuning by using Bayesian sampling for an Azure ML Python SDK v2-based model training from a notebook. The notebook is in an Azure Machine Learning workspace. The notebook uses a training
script that runs on a compute cluster with 20 nodes.
The code implements Bandit termination policy with slack_factor set to 02 and a sweep job with max_concurrent_trials set to 10.
You must increase effectiveness of the tuning process by improving sampling convergence.
You need to select which sampling convergence to use.
What should you select?
A. Set the value of slack.factor of earty.termination policy to 0.1.
B. Set the value of max_concurrent_trials to 4.
C. Set the value of slack_factor of eartyjermination policy to 0.9.
D. Set the value of max.concurrentjrials to 20.
-
Question 34:
You have an Azure Machine Learning workspace. You build a deep learning model.
You need to publish a GPU-enabled model as a web service.
Which two compute targets can you use? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A. Azure Kubernetes Service (AKS)
B. Azure Container Instances (ACI)
C. Local web service
D. Azure Machine Learning compute clusters
-
Question 35:
HOTSPOT
You need to build a feature extraction strategy for the local models.
How should you complete the code segment? To answer, select the appropriate options in the answer area;
NOTE: Each correct selection is worth one point.
Hot Area:

-
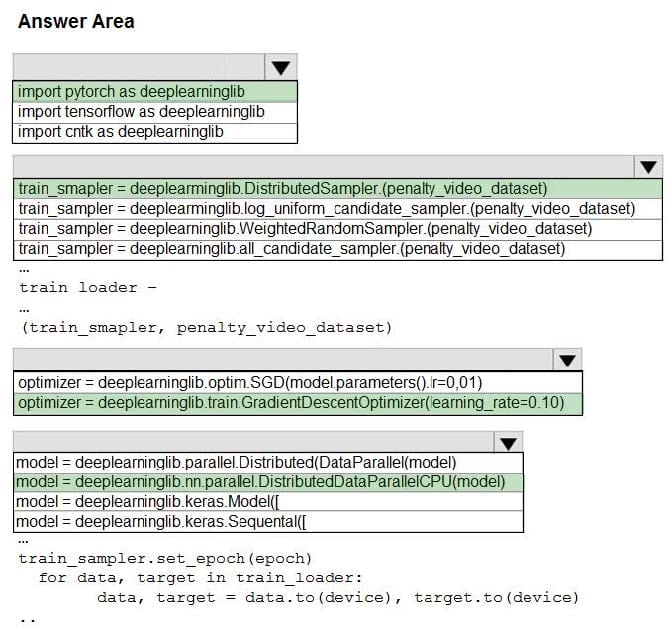
Question 36:
You need to use the Python language to build a sampling strategy for the global penalty detection models. How should you complete the code segment? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
Hot Area:
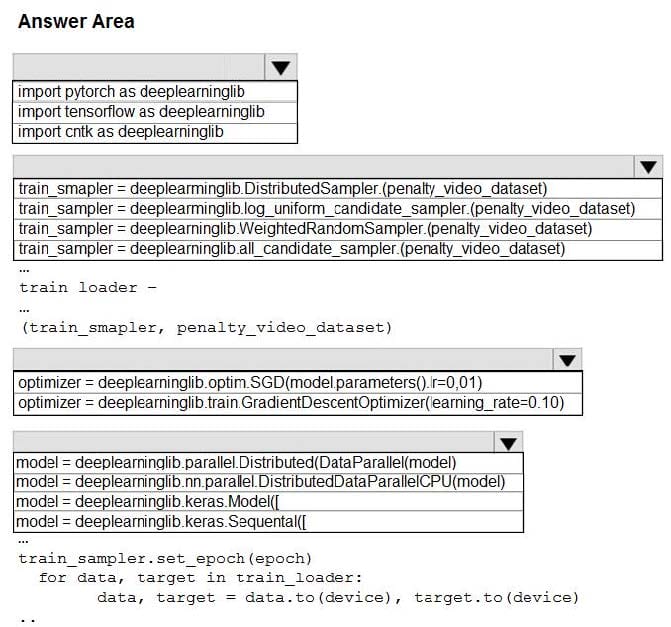
-
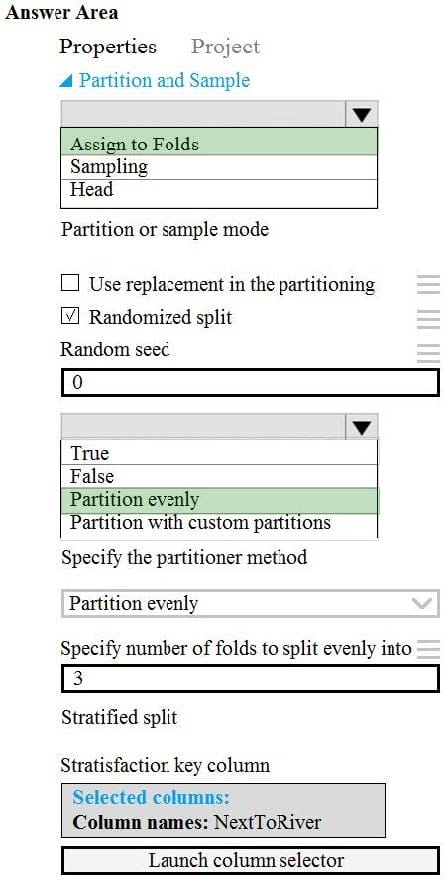
Question 37:
HOTSPOT
You need to identify the methods for dividing the data according to the testing requirements.
Which properties should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
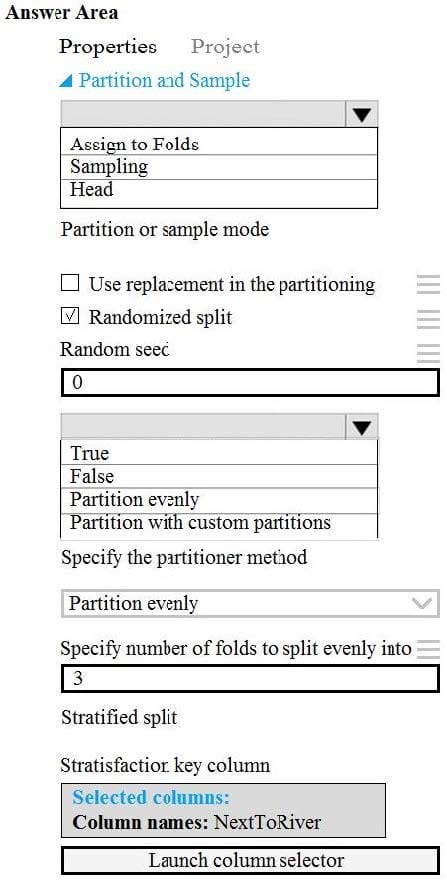
-
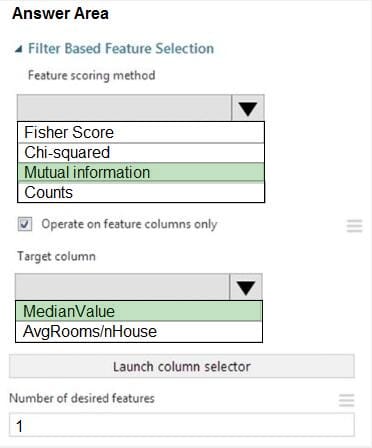
Question 38:
You need to configure the Feature Based Feature Selection module based on the experiment requirements and datasets.
How should you configure the module properties? To answer, select the appropriate options in the dialog box in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
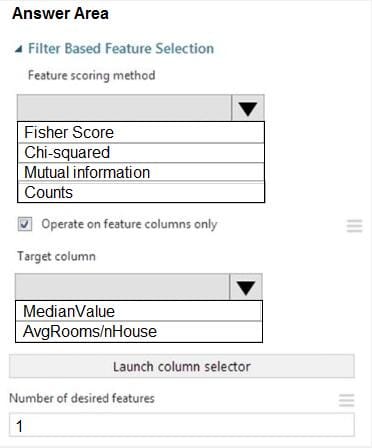
-
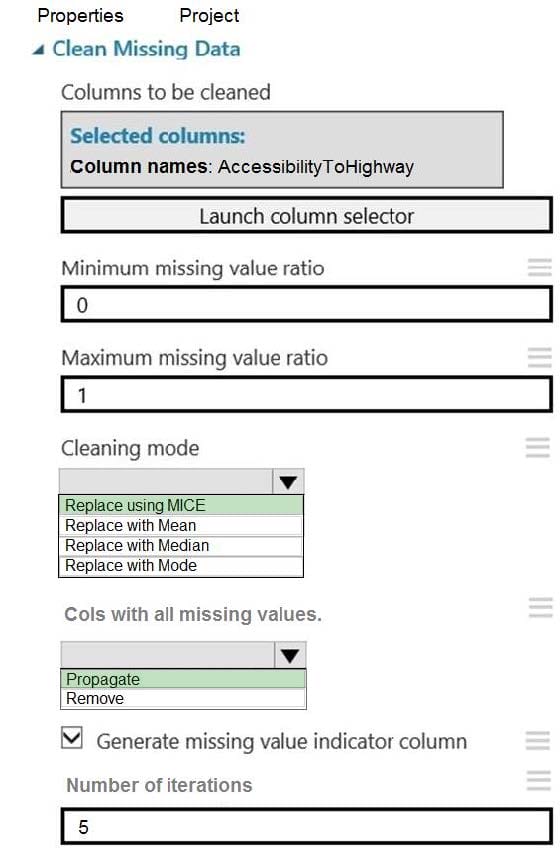
Question 39:
You need to replace the missing data in the AccessibilityToHighway columns.
How should you configure the Clean Missing Data module? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
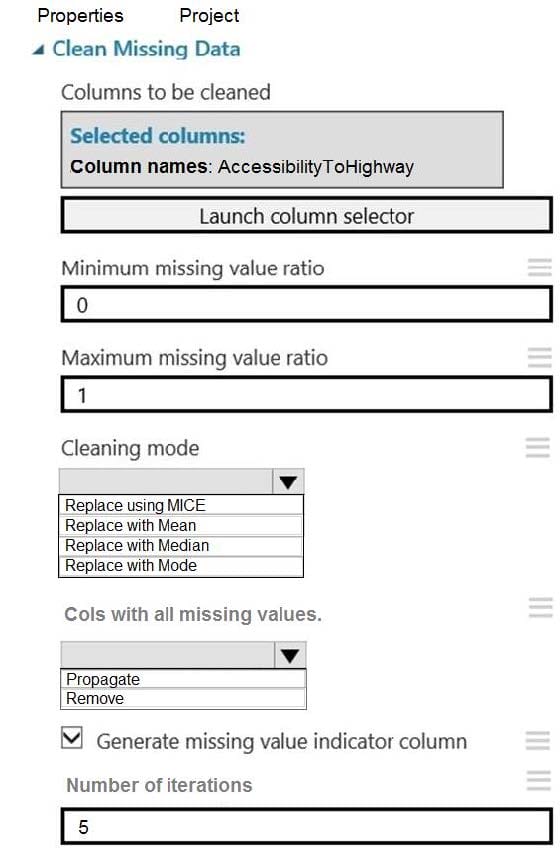
-
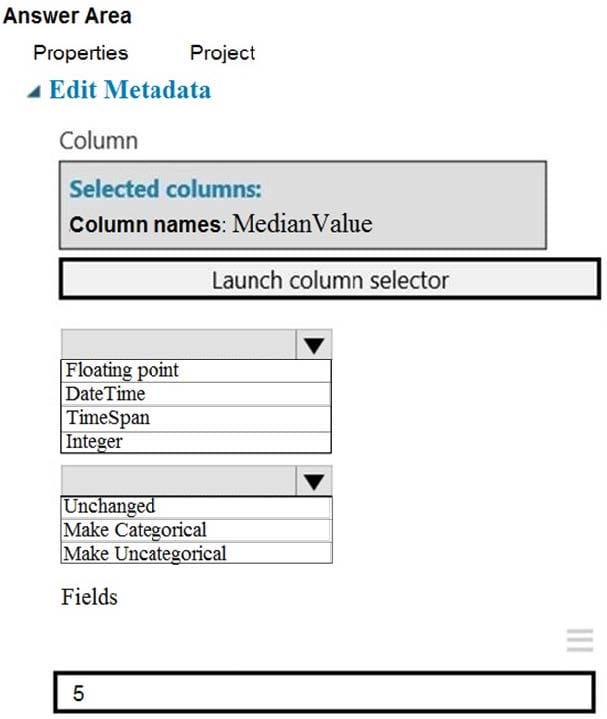
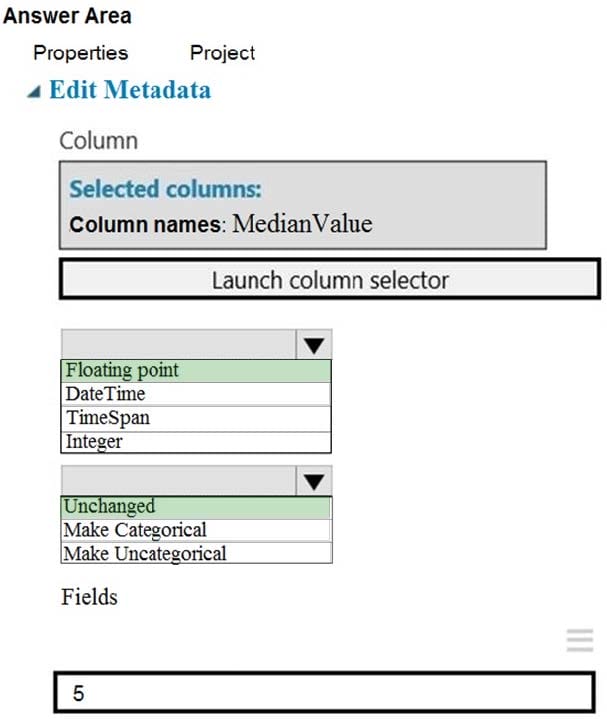
Question 40:
HOTSPOT
You need to configure the Edit Metadata module so that the structure of the datasets match.
Which configuration options should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:

Related Exams:
62-193
Technology Literacy for Educators70-243
Administering and Deploying System Center 2012 Configuration Manager70-355
Universal Windows Platform – App Data, Services, and Coding Patterns77-420
Excel 201377-427
Excel 2013 Expert Part One77-725
Word 2016 Core Document Creation, Collaboration and Communication77-726
Word 2016 Expert Creating Documents for Effective Communication77-727
Excel 2016 Core Data Analysis, Manipulation, and Presentation77-728
Excel 2016 Expert: Interpreting Data for Insights77-731
Outlook 2016 Core Communication, Collaboration and Email Skills
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Microsoft exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DP-100 exam preparations and Microsoft certification application, do not hesitate to visit our Vcedump.com to find your solutions here.