Exam Details
Exam Code
:DP-203Exam Name
:Data Engineering on Microsoft AzureCertification
:Microsoft CertificationsVendor
:MicrosoftTotal Questions
:398 Q&AsLast Updated
:Mar 22, 2025
Microsoft Microsoft Certifications DP-203 Questions & Answers
-
Question 1:
HOTSPOT
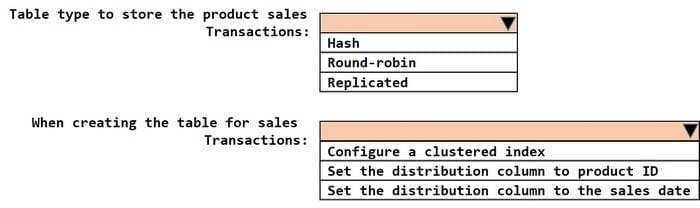
You need to design a data storage structure for the product sales transactions. The solution must meet the sales transaction dataset requirements.
What should you include in the solution? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
-
Question 2:
HOTSPOT
You need to design an analytical storage solution for the transactional data. The solution must meet the sales transaction dataset requirements.
What should you include in the solution? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:

-
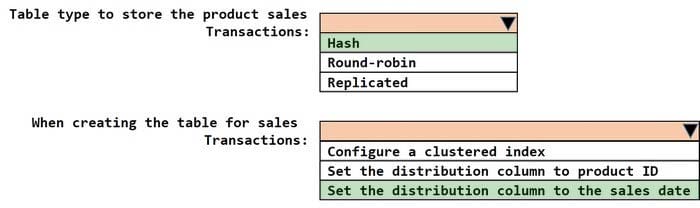
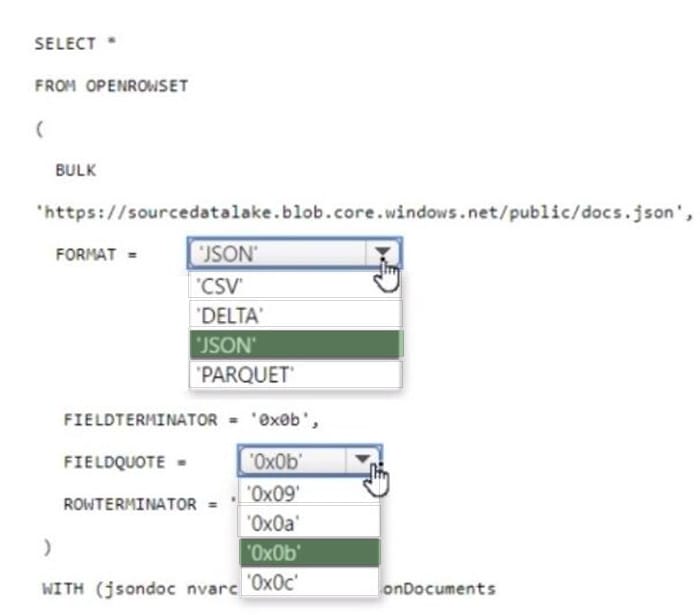
Question 3:
HOTSPOT
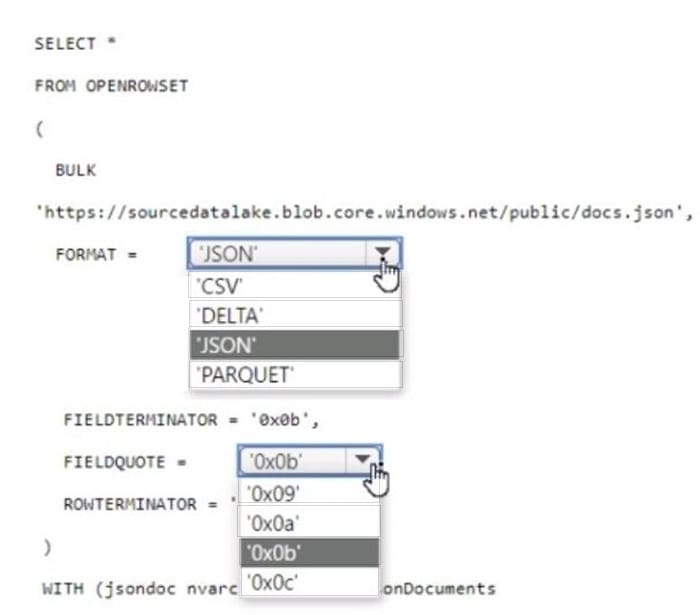
You have an Azure Synapse serverless SQL pool.
You need to read JSON documents from a file by using the OPENROWSET function.
How should you complete the query? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
-
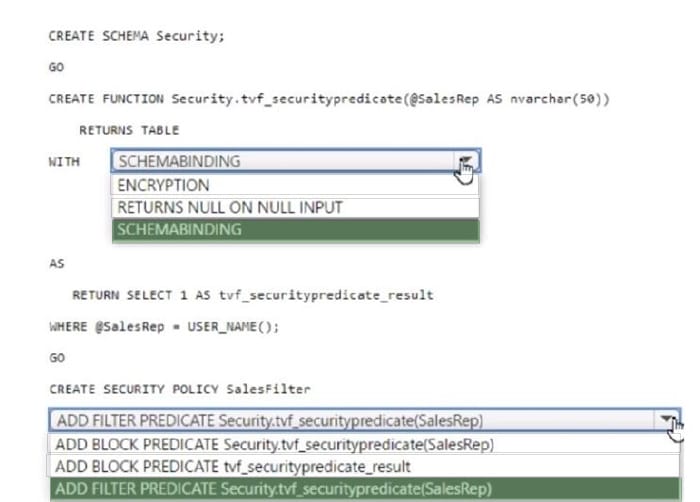
Question 4:
HOTSPOT
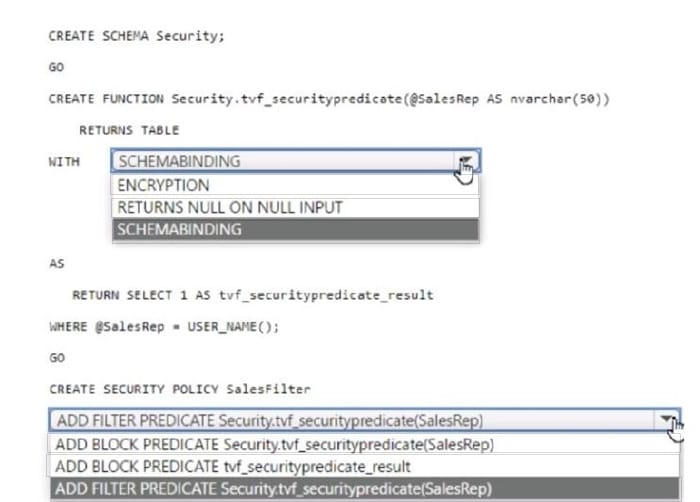
You have an Azure Synapse Analytics dedicated SQL pool that contains a table named Sales.Orders. Sales.Orders contains a column named SalesRep.
You plan to implement row-level security (RLS) for Sales.Orders.
You need to create the security policy that will be used to implement RLS. The solution must ensure that sales representatives only see rows for which the value of the SalesRep column matches their username.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
-
Question 5:
HOTSPOT
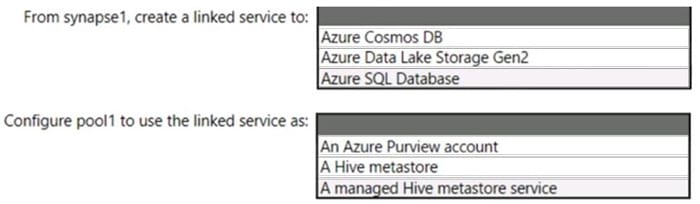
You have an Azure subscription that contains an Azure Databricks workspace named databricks1 and an Azure Synapse Analytics workspace named synapse1. The synapse1 workspace contains an Apache Spark pool named pool1.
You need to share an Apache Hive catalog of pool1 with databricks1.
What should you do? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
-
Question 6:
A company purchases IoT devices to monitor manufacturing machinery. The company uses an Azure IoT Hub to communicate with the IoT devices.
The company must be able to monitor the devices in real-time.
You need to design the solution.
What should you recommend?
A. Azure Analysis Services using Microsoft Visual Studio
B. Azure Data Factory instance using Azure PowerShell
C. Azure Analysis Services using Azure PowerShell
D. Azure Stream Analytics cloud job using Azure Portal
-
Question 7:
You have an Azure Synapse Analytics dedicated SQL pool named Pool1. Pool1 contains a fact table named Table1.
You need to identify the extent of the data skew in Table1.
What should you do in Synapse Studio?
A. Connect to the built-in pool and query sys.dm_pdw_nodes_db_partition_stats.
B. Connect to Pool1 and run DBCC PDW_SHOWSPACEUSED.
C. Connect to Pool1 and query sys.dm_pdw_node_status.
D. Connect to the built-in pool and query sys.dm_pdw_sys_info.
-
Question 8:
You have an Azure subscription that contains an Azure Data Lake Storage Gen2 account named account1 and an Azure Synapse Analytics workspace named workspace1.
You need to create an external table in a serverless SQL pool in workspace1. The external table will reference CSV files stored in account1. The solution must maximize performance.
How should you configure the external table?
A. Use a native external table and authenticate by using a shared access signature (SAS).
B. Use a native external table and authenticate by using a storage account key.
C. Use an Apache Hadoop external table and authenticate by using a shared access signature (SAS).
D. Use an Apache Hadoop external table and authenticate by using a service principal in Microsoft Azure Active Directory (Azure AD), part of Microsoft Entra.
-
Question 9:
What should you recommend using to secure sensitive customer contact information?
A. Transparent Data Encryption (TDE)
B. row-level security
C. column-level security
D. data sensitivity labels
-
Question 10:
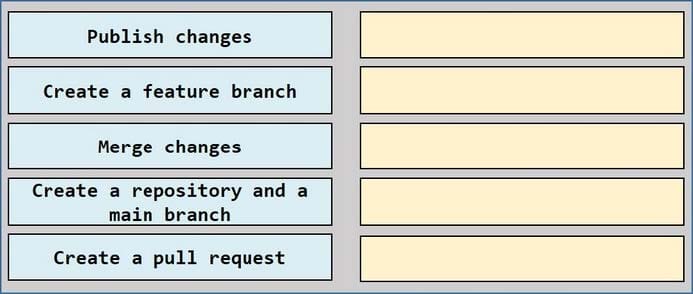
DRAG DROP
You need to implement versioned changes to the integration pipelines. The solution must meet the data integration requirements.
In which order should you perform the actions? To answer, move all actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:



Related Exams:
62-193
Technology Literacy for Educators70-243
Administering and Deploying System Center 2012 Configuration Manager70-355
Universal Windows Platform – App Data, Services, and Coding Patterns77-420
Excel 201377-427
Excel 2013 Expert Part One77-725
Word 2016 Core Document Creation, Collaboration and Communication77-726
Word 2016 Expert Creating Documents for Effective Communication77-727
Excel 2016 Core Data Analysis, Manipulation, and Presentation77-728
Excel 2016 Expert: Interpreting Data for Insights77-731
Outlook 2016 Core Communication, Collaboration and Email Skills
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Microsoft exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DP-203 exam preparations and Microsoft certification application, do not hesitate to visit our Vcedump.com to find your solutions here.