Administering Relational Databases on Microsoft Azure
Exam Details
Exam Code
:DP-300
Exam Name
:Administering Relational Databases on Microsoft Azure
Certification
:Microsoft Certifications
Vendor
:Microsoft
Total Questions
:368 Q&As
Last Updated
:Jul 08, 2025
Microsoft Microsoft Certifications DP-300 Questions & Answers
Question 261:
HOTSPOT
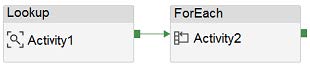
You have an Azure data factory that has two pipelines named PipelineA and PipelineB.
PipelineA has four activities as shown in the following exhibit.
PipelineB has two activities as shown in the following exhibit.
You create an alert for the data factory that uses Failed pipeline runs metrics for both pipelines and all failure types. The metric has the following settings:
1.
Operator: Greater than
2.
Aggregation type: Total
3.
Threshold value: 2
4.
Aggregation granularity (Period): 5 minutes
5.
Frequency of evaluation: Every 5 minutes
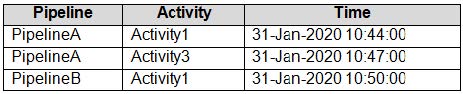
Data Factory monitoring records the failures shown in the following table.
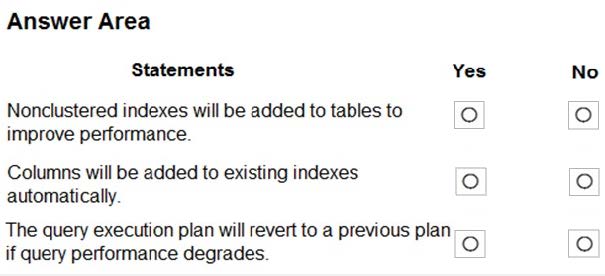
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
You have an Azure Data Factory instance named ADF1 and two Azure Synapse Analytics workspaces named WS1 and WS2.
ADF1 contains the following pipelines:
1.
P1:Uses a copy activity to copy data from a nonpartitioned table in a dedicated SQL pool of WS1 to an Azure Data Lake Storage Gen2 account
2.
P2:Uses a copy activity to copy data from text-delimited files in an Azure Data Lake Storage Gen2 account to a nonpartitioned table in a dedicated SQL pool of WS2
You need to configure P1 and P2 to maximize parallelism and performance.
Which dataset settings should you configure for the copy activity of each pipeline? To answer, select the appropriate options in the answer area.
Hot Area:
Correct Answer:
P1: Set the Partition option to Dynamic Range.
The SQL Server connector in copy activity provides built-in data partitioning to copy data in parallel.
P2: Set the Copy method to PolyBase
Polybase is the most efficient way to move data into Azure Synapse Analytics. Use the staging blob feature to achieve high load speeds from all types of data stores, including Azure Blob storage and Data Lake Store. (Polybase supports
Azure Blob storage and Azure Data Lake Store by default.)
You have an Azure Data Lake Storage Gen2 container.
Data is ingested into the container, and then transformed by a data integration application. The data is NOT modified after that. Users can read files in the container but cannot modify the files.
You need to design a data archiving solution that meets the following requirements:
1.
New data is accessed frequently and must be available as quickly as possible.
2.
Data that is older than five years is accessed infrequently but must be available within one second when requested.
3.
Data that us older than seven years is NOT accessed. After seven years, the data must be persisted at the lowest cost possible.
4.
Costs must be minimized while maintaining the required availability.
How should you manage the data? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:
Box 1: Move to cool storage
The cool access tier has lower storage costs and higher access costs compared to hot storage. This tier is intended for data that will remain in the cool tier for at least 30 days. Example usage scenarios for the cool access tier include:
Short-term backup and disaster recovery
Older data not used frequently but expected to be available immediately when accessed
Large data sets that need to be stored cost effectively, while more data is being gathered for future processing
Note: Hot - Optimized for storing data that is accessed frequently.
Cool - Optimized for storing data that is infrequently accessed and stored for at least 30 days.
Archive - Optimized for storing data that is rarely accessed and stored for at least 180 days with flexible latency requirements, on the order of hours.
Box 2: Move to archive storage
Example usage scenarios for the archive access tier include:
Long-term backup, secondary backup, and archival datasets
Original (raw) data that must be preserved, even after it has been processed into final usable form
Compliance and archival data that needs to be stored for a long time and is hardly ever accessed
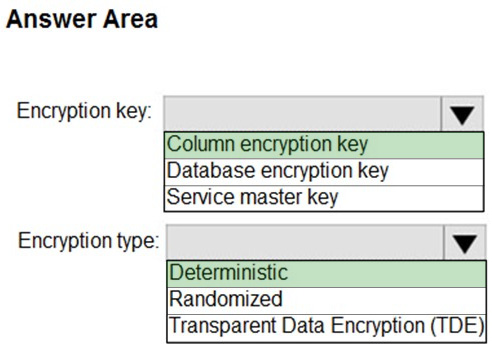
You have an Azure SQL database named DB1 that contains two tables named Table1 and Table2. Both tables contain a column named a Column1. Column1 is used for joins by an application named App1.
You need to protect the contents of Column1 at rest, in transit, and in use.
How should you protect the contents of Column1? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:
Explanation:
Box 1: Column encryption Key
Always Encrypted uses two types of keys: column encryption keys and column master keys. A column encryption key is used to encrypt data in an encrypted column. A column master key is a key-protecting key that encrypts one or more
column encryption keys.
Incorrect Answers:
TDE encrypts the storage of an entire database by using a symmetric key called the Database Encryption Key (DEK).
Box 2: Deterministic
Always Encrypted is a feature designed to protect sensitive data, such as credit card numbers or national identification numbers (for example, U.S. social security numbers), stored in Azure SQL Database or SQL Server databases. Always
Encrypted allows clients to encrypt sensitive data inside client applications and never reveal the encryption keys to the Database Engine (SQL Database or SQL Server).
Always Encrypted supports two types of encryption: randomized encryption and deterministic encryption.
Deterministic encryption always generates the same encrypted value for any given plain text value. Using deterministic encryption allows point lookups, equality joins, grouping and indexing on encrypted columns.
Incorrect Answers:
1.
Randomized encryption uses a method that encrypts data in a less predictable manner. Randomized encryption is more secure, but prevents searching, grouping, indexing, and joining on encrypted columns.
2.
Transparent data encryption (TDE) helps protect Azure SQL Database, Azure SQL Managed Instance, and Azure Synapse Analytics against the threat of malicious offline activity by encrypting data at rest. It performs real-time encryption and decryption of the database, associated backups, and transaction log files at rest without requiring changes to the application.
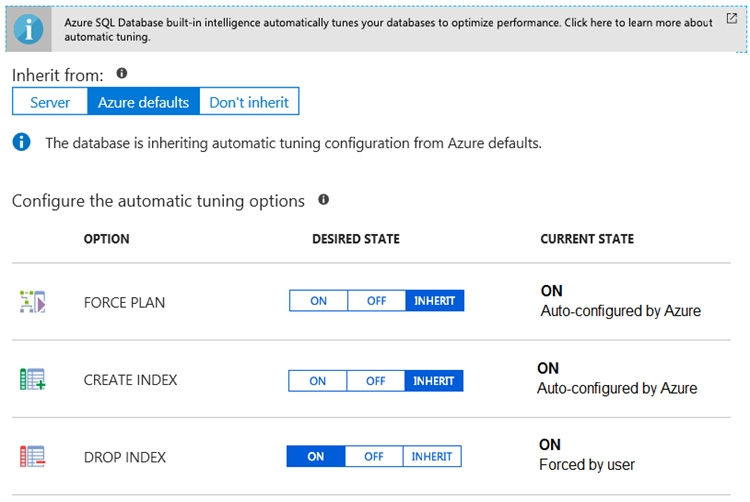
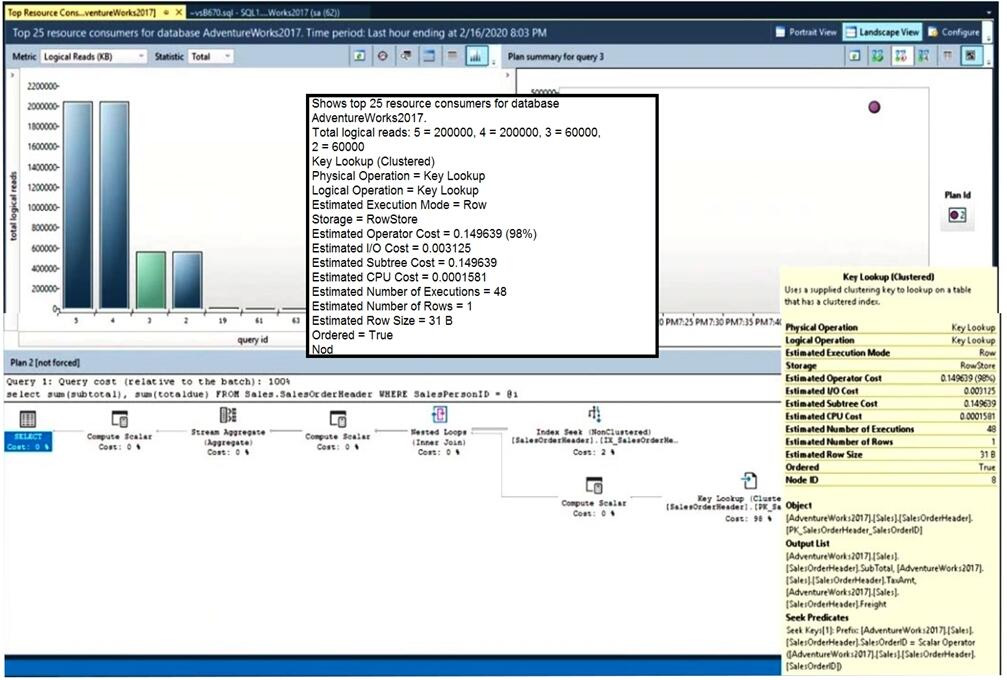
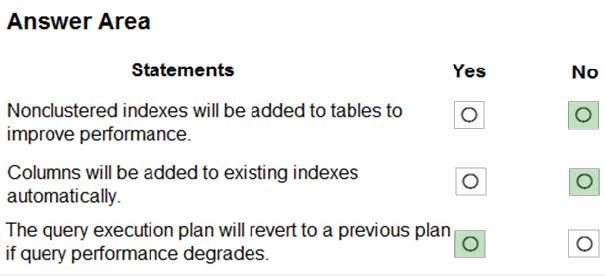
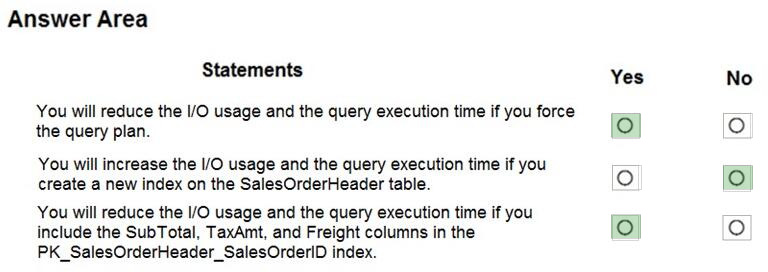
You have an Azure SQL database named DB1. The automatic tuning options for DB1 are configured as shown in the following exhibit.
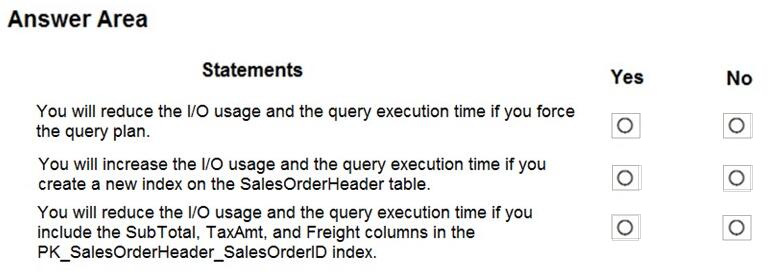
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:
Box 1: No
By default CREATE INDEX is disabled. It is here configured as INHERIT so it is disabled.
Box 2: No
By default DROP INDEX is disabled.
Box 3: Yes
FORCE LAST GOOD PLAN (automatic plan correction) - Identifies Azure SQL queries using an execution plan that is slower than the previous good plan, and queries using the last known good plan instead of the regressed plan.
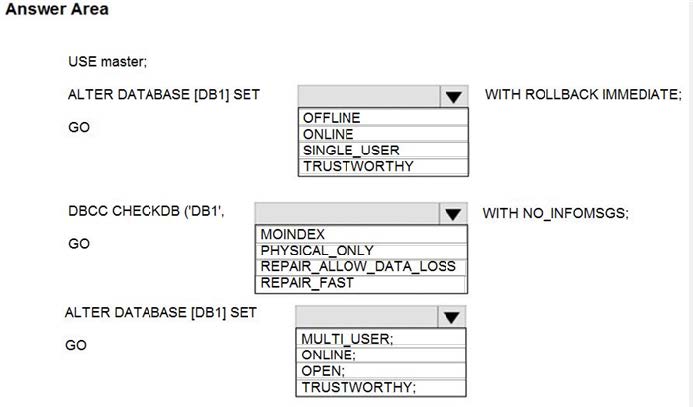
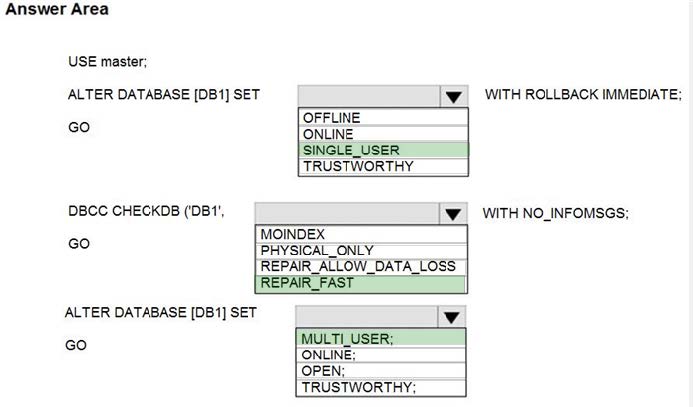
You have SQL Server on an Azure virtual machine that contains a database named DB1.
The database reports a CHECKSUM error.
You need to recover the database.
How should you complete the statements? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:
Box 1: SINGLE_USER
The specified database must be in single-user mode to use one of the following repair options.
Box 2: REPAIR_ALLOW_DATA_LOSS
REPAIR_ALLOW_DATA_LOSS tries to repair all reported errors. These repairs can cause some data loss.
Note: The REPAIR_ALLOW_DATA_LOSS option is a supported feature but it may not always be the best option for bringing a database to a physically consistent state. If successful, the REPAIR_ALLOW_DATA_LOSS option may result in
some data loss. In fact, it may result in more data lost than if a user were to restore the database from the last known good backup.
Incorrect Answers:
REPAIR_FAST
Maintains syntax for backward compatibility only. No repair actions are performed.
Box 3: MULTI_USER
MULTI_USER
All users that have the appropriate permissions to connect to the database are allowed.
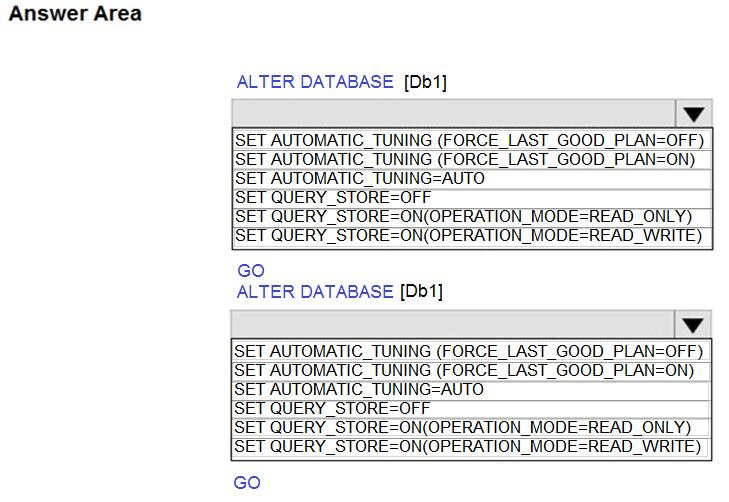
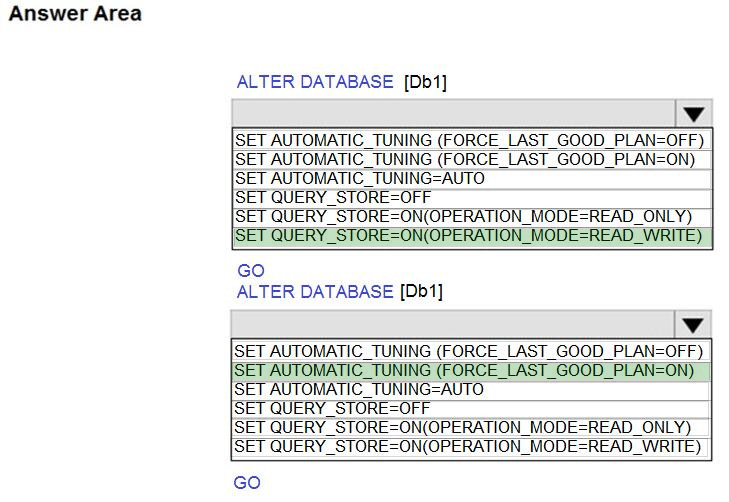
You have SQL Server on an Azure virtual machine that contains a database named Db1.
You need to enable automatic tuning for Db1.
How should you complete the statements? To answer, select the appropriate answer in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:
Box 1: SET QUERY_STORE = ON (OPERATION MODE = READ_WRITE);
Must enable the Query Store.
Incorrect:
If the server may be Azure SQL or Managed Instance then the response should be SET AUTOMATIC_TUNNIG=AUTO, but as it is a SQL server the Query store needs to be first enabled.
Box 2: SET AUTOMATIC_TUNING (FORCE_LAST_GOOD_PLAN = ON)
To configure individual automatic tuning options via T-SQL, connect to the database and execute the query such as this one:
ALTER DATABASE current SET AUTOMATIC_TUNING (FORCE_LAST_GOOD_PLAN = ON)
Setting the individual tuning option to ON will override any setting that database inherited and enable the tuning option. Setting it to OFF will also override any setting that database inherited and disable the tuning option.
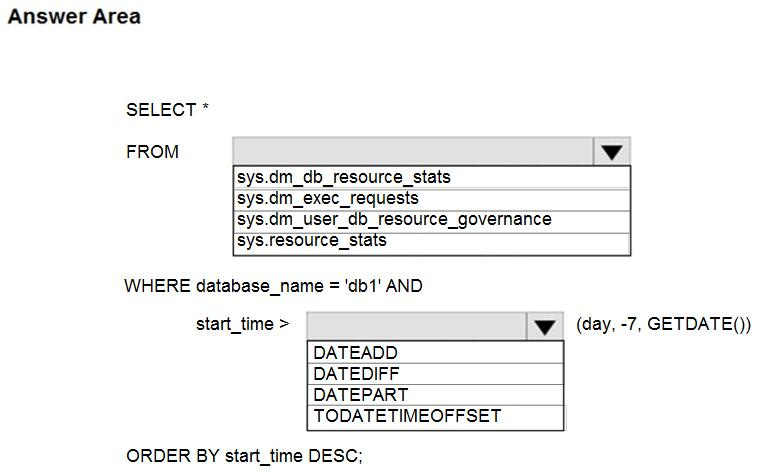
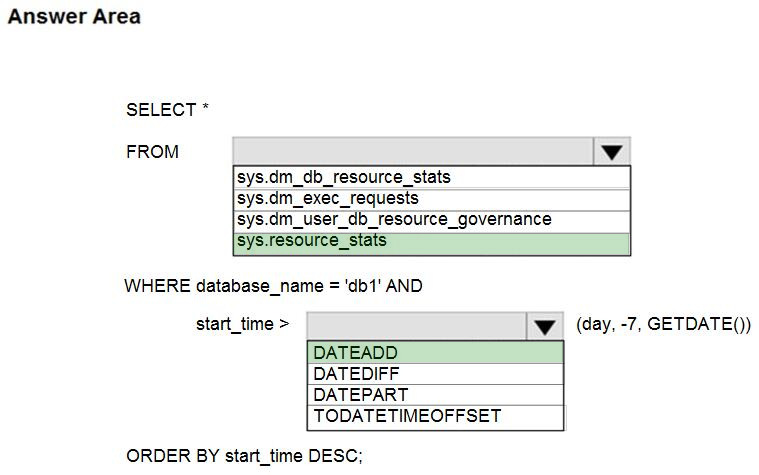
You need to retrieve the resource usage of db1 from the last week.
How should you complete the statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:
Box 1: sys.resource_stats
sys.resource_stats returns CPU usage and storage data for an Azure SQL Database. It has database_name and start_time columns.
Box 2: DateAdd
The following example returns all databases that are averaging at least 80% of compute utilization over the last one week.
DECLARE @s datetime;
DECLARE @e datetime;
SET @s= DateAdd(d,-7,GetUTCDate());
SET @e= GETUTCDATE();
SELECT database_name, AVG(avg_cpu_percent) AS Average_Compute_Utilization
FROM sys.resource_stats
WHERE start_time BETWEEN @s AND @e
GROUP BY database_name
HAVING AVG(avg_cpu_percent) >= 80
Incorrect Answers:
sys.dm_exec_requests:
sys.dm_exec_requests returns information about each request that is executing in SQL Server. It does not have a column named database_name.
sys.dm_db_resource_stats:
sys.dm_db_resource_stats does not have any start_time column.
Note: sys.dm_db_resource_stats returns CPU, I/O, and memory consumption for an Azure SQL Database database. One row exists for every 15 seconds, even if there is no activity in the database. Historical data is maintained for
approximately one hour.
Sys.dm_user_db_resource_governance returns actual configuration and capacity settings used by resource governance mechanisms in the current database or elastic pool. It does not have any start_time column.
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Microsoft exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DP-300 exam preparations and Microsoft certification application, do not hesitate to visit our Vcedump.com to find your solutions here.