Exam Details
Exam Code
:DP-100Exam Name
:Designing and Implementing a Data Science Solution on AzureCertification
:Microsoft CertificationsVendor
:MicrosoftTotal Questions
:564 Q&AsLast Updated
:Jul 05, 2025
Microsoft Microsoft Certifications DP-100 Questions & Answers
-
Question 371:
You plan to build a team data science environment. Data for training models in machine learning pipelines will be over 20 GB in size. You have the following requirements:
1.
Models must be built using Caffe2 or Chainer frameworks.
2.
Data scientists must be able to use a data science environment to build the machine learning pipelines and train models on their personal devices in both connected and disconnected network environments.
Personal devices must support updating machine learning pipelines when connected to a network.
You need to select a data science environment.
Which environment should you use?
A. Azure Machine Learning Service
B. Azure Machine Learning Studio
C. Azure Databricks
D. Azure Kubernetes Service (AKS)
-
Question 372:
You manage an Azure Machine Learning workspace. The workspace includes an Azure Machine Learning Kubernetes compute target configured as an Azure Kubernetes Service (AKS) cluster named AKS1. AKS1 is configured to enable the
targeting of different nodes to train workloads.
You must run a command job on AKS1 by using the Azure ML Python SDK v2. The command job must select different types of compute nodes. The compute node types must be specified by using a command parameter.
You need to configure the command parameter.
Which parameter should you use?
A. environment
B. compute
C. limits
D. instance_type
-
Question 373:
You manage an Azure Machine Learning workspace named workspace1.
You must develop Python SDK v2 code to add a compute instance to workspace1. The code must import all required modules and call the constructor of the ComputeInstance class.
You need to add the instantiated compute instance to workspace1.
What should you use?
A. constructor of the azure.ai.ml.ComputeSchedule class
B. constructor of the azure.ai.ml.ComputePowerAction enum
C. begin_create_or_update method of an instance of the azure.ai.ml.MLCIient class
D. set_resources method of an instance of the azure.ai.ml.Command class
-
Question 374:
You create a workspace to include a compute instance by using Azure Machine Learning Studio. You are developing a Python SDK v2 notebook in the workspace.
You need to use Intellisense in the notebook.
What should you do?
A. Stop the compute instance.
B. Start the compute instance.
C. Run a %pip magic function on the compute instance.
D. Run a !pip magic function on the compute instance.
-
Question 375:
You manage an Azure Machine Learning workspace.
You need to define an environment from a Docker image by using the Azure Machine Learning Python SDK v2.
Which parameter should you use?
A. properties
B. image
C. build
D. conda_file
-
Question 376:
You create an Azure Machine Learning managed compute resource. The compute resource is configured as follows:
Minimum nodes: 2 Maximum nodes: 4 You must decrease the minimum number of nodes and increase the maximum number of nodes to the following values: Minimum nodes: 0
Maximum nodes: 8
You need to reconfigure the compute resource.
Which three methods can you use? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A. Azure Machine Learning designer
B. MLClient class in Python SDK v2
C. Azure Machine Learning studio
D. Azure CLI ml extension v2
E. BuildContext class in Python SDK v2
-
Question 377:
You plan to use automated machine learning by using Azure Machine Learning Python SDK v2 to train a regression model. You have data that has features with missing values, and categorical features with few distinct values.
You need to control whether automated machine learning automatically imputes missing values and encode categorical features as part of the training task.
Which enum of the automl package should you use?
A. ForecastHorizonMode
B. RegressionModels
C. FeaturizationMode
D. RegressionPrimaryMetrics
-
Question 378:
You use Azure Machine Learning designer to load the following datasets into an experiment: Dataset1

Dataset2
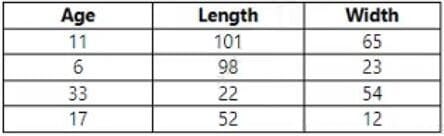
You need to create a dataset that has the same columns and header row as the input datasets and contains all rows from both input datasets.
Solution: Use the Join Data module.
Does the solution meet the goal?
A. Yes
B. No
-
Question 379:
You are developing a two-step Azure Machine Learning pipeline by using the Azure Machine Learning SDK for Python. You need to register the output of the pipeline as a new version of a named dataset after the run has been completed. What should you implement?
A. the as_input method of the OutputDatasetConfig class
B. the register_on_complete method of the OutputDatasetConfig class
C. the as_mount method of the DatasetConsumptionConfig class
D. the as_download method of the DatasetConsumptionConfig class
-
Question 380:
You are implementing hyperparameter tuning by using Bayesian sampling for a model training from a notebook. The notebook is in an Azure Machine Learning workspace that uses a compute cluster with 20 nodes.
The code implements Bandit termination policy with slack factor set to 0.2 and the HyperDriveConfig class instance with max_concurrent_runs set to 10.
You must increase effectiveness of the tuning process by improving sampling convergence.
You need to select which sampling convergence to use.
What should you select?
A. Set the value of slack factor of early_termination_policy to 0.9.
B. Set the value of max_concurrent_runs of HyperDriveConfig to 4.
C. Set the value of slack factor of early_termination_policy to 0.1.
D. Set the value of max_concurrent_runs of HyperDriveConfig to 20.
Related Exams:
62-193
Technology Literacy for Educators70-243
Administering and Deploying System Center 2012 Configuration Manager70-355
Universal Windows Platform – App Data, Services, and Coding Patterns77-420
Excel 201377-427
Excel 2013 Expert Part One77-725
Word 2016 Core Document Creation, Collaboration and Communication77-726
Word 2016 Expert Creating Documents for Effective Communication77-727
Excel 2016 Core Data Analysis, Manipulation, and Presentation77-728
Excel 2016 Expert: Interpreting Data for Insights77-731
Outlook 2016 Core Communication, Collaboration and Email Skills
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Microsoft exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DP-100 exam preparations and Microsoft certification application, do not hesitate to visit our Vcedump.com to find your solutions here.