Exam Details
Exam Code
:DP-100Exam Name
:Designing and Implementing a Data Science Solution on AzureCertification
:Microsoft CertificationsVendor
:MicrosoftTotal Questions
:564 Q&AsLast Updated
:Jun 26, 2025
Microsoft Microsoft Certifications DP-100 Questions & Answers
-
Question 381:
You register a model in an Azure Machine Learning workspace by running the following code:

You are creating a scoring script to use in a real-time service for the model.
You need to write code in the scoring script to set the path of the registered model so that it can be loaded by the service. You include the necessary import statements.
Which code segment should you use?
A. path = Model.get_model_path(`loan_model')
B. path = `model.pkl'
C. path = ws.models(`loan_model')
D. path = `outputs/model.pkl'
-
Question 382:
You are using a ScriptRunConfig object to configure an experiment that uses a script to train a machine learning model.
The script must apply a regularization rate hyperparameter to the algorithm that is used to train the model.
You need to pass the regularization rate in a variable named reg_rate to the script.
Which code segment should you use?
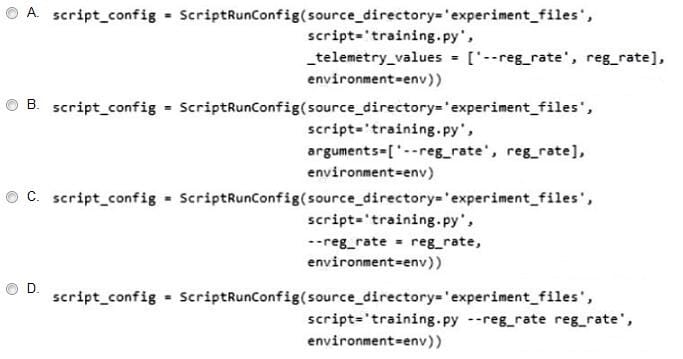
A. Option A
B. Option B
C. Option C
D. Option D
-
Question 383:
You are implementing hyperparameter tuning for a model training from a notebook. The notebook is in an Azure Machine Learning workspace.
You must configure a grid sampling method over the search space for the num_hidden_layers and batch_size hyperparameters.
You need to identify the hyperparameters for the grid sampling.
Which hyperparameter sampling approach should you use?
A. uniform
B. qlognormal
C. choice
D. normal
-
Question 384:
You create an Azure Machine Learning workspace. You are implementing hyperparameter tuning for a model training from a notebook.
You must configure a Bandit termination policy that provides the following outcome:
If the value of the primary metric of AUC is 0.8 at the point of evaluation intervals, any run with the primary metric value below 0.66 will be terminated.
You need to identify which Bandit termination policy configuration to use.
What should you identify?
A. Set slack_amount to 0.2.
B. Set slack_factor to 0.1.
C. Set slack_factor to 0.2.
D. Set slack_amount to 0.1.
-
Question 385:
You need to evaluate the potential risk of exposing personal information based on the values of epsilon and delta for differential privacy. You create a privacy report. What does an epsilon value greater than one represent?
A. The privacy of data is preserved and there is limited impact on data accuracy.
B. There is a high risk of exposing the actual data that is uses to generate the report.
C. The data used in the report is very noisy.
-
Question 386:
You create an Azure Machine Learning workspace named workspaces. You create a Python SDK v2 notebook to perform custom model training in workspaces.
You need to run the notebook from Azure Machine Learning Studio in workspaces.
What should you provision first?
A. default storage account
B. real-time endpoint
C. Azure Machine Learning compute cluster
D. Azure Machine Learning compute instance
-
Question 387:
You plan to run a script as an experiment. The script uses modules from the SciPy library and several Python packages that are not typically installed in a default conda environment.
You plan to run the experiment on your local workstation for small datasets and scale out the experiment by running it on more powerful remote compute dusters for larger datasets.
You need to ensure that the experiment runs successfully on local and remote compute with the least administrative effort.
What should you do?
A. Leave the environment unspecified for the experiment. Run the expenment by using the default environment.
B. Create a config.yaml file that defines the required conda packages and save the file in the experiment folder.
C. Create and register an environment that includes the required packages. Use this environment for all experiment jobs.
D. Create a virtual machine (VM) by using the required Python configuration and attach the VM as a compute target. Use this compute target for all experiment runs.
-
Question 388:
You create an Azure Machine Learning workspace named workspace1. The workspace contains a Python SDK v2 notebook that uses MLflow to collect model training metrics and artifacts from your local computer.
You must reuse the notebook to run on Azure Machine Learning compute instance in workspace1.
You need to continue to log metrics and artifacts from your data science code.
What should you do?
A. Instantiate the job class.
B. Instantiate the MLCIient class.
C. Log in to workspace1.
D. Configure the tracking URL.
-
Question 389:
You use Azure Machine Learning to train a model.
You must use Bayesian sampling to tune hyperparameters.
You need to select a learning_rate parameter distribution.
Which two distributions can you use? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A. Uniform
B. Choice
C. QNormal
D. Normal
E. LogUniform
-
Question 390:
You create an Azure Machine learning workspace.
You must use the Azure Machine Learning Python SDK v2 to define the search space for discrete hyperparameters. The hyperparameters must consist of a list of predetermined, comma-separated integer values.
You need to import the class from the azure.ai.ml.sweep package used to create the list of values.
Which class should you import?
A. Choice
B. Randint
C. Uniform
D. Normal
Related Exams:
62-193
Technology Literacy for Educators70-243
Administering and Deploying System Center 2012 Configuration Manager70-355
Universal Windows Platform – App Data, Services, and Coding Patterns77-420
Excel 201377-427
Excel 2013 Expert Part One77-725
Word 2016 Core Document Creation, Collaboration and Communication77-726
Word 2016 Expert Creating Documents for Effective Communication77-727
Excel 2016 Core Data Analysis, Manipulation, and Presentation77-728
Excel 2016 Expert: Interpreting Data for Insights77-731
Outlook 2016 Core Communication, Collaboration and Email Skills
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Microsoft exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DP-100 exam preparations and Microsoft certification application, do not hesitate to visit our Vcedump.com to find your solutions here.