Exam Details
Exam Code
:DP-203Exam Name
:Data Engineering on Microsoft AzureCertification
:Microsoft CertificationsVendor
:MicrosoftTotal Questions
:398 Q&AsLast Updated
:Apr 07, 2025
Microsoft Microsoft Certifications DP-203 Questions & Answers
-
Question 221:
You are monitoring an Azure Stream Analytics job by using metrics in Azure.
You discover that during the last 12 hours, the average watermark delay is consistently greater than the configured late arrival tolerance.
What is a possible cause of this behavior?
A. Events whose application timestamp is earlier than their arrival time by more than five minutes arrive as inputs.
B. There are errors in the input data.
C. The late arrival policy causes events to be dropped.
D. The job lacks the resources to process the volume of incoming data.
-
Question 222:
You use Azure Stream Analytics to receive data from Azure Event Hubs and to output the data to an Azure Blob Storage account.
You need to output the count of records received from the last five minutes every minute.
Which windowing function should you use?
A. Session
B. Tumbling
C. Sliding
D. Hopping
-
Question 223:
You have the following Azure Data Factory pipelines:
1.
Ingest Data from System1
2.
Ingest Data from System2
3.
Populate Dimensions
4.
Populate Facts
Ingest Data from System1 and Ingest Data from System2 have no dependencies. Populate Dimensions must execute after Ingest Data from System1 and Ingest Data from System2. Populate Facts must execute after Populate Dimensions pipeline. All the pipelines must execute every eight hours.
What should you do to schedule the pipelines for execution?
A. Add an event trigger to all four pipelines.
B. Add a schedule trigger to all four pipelines.
C. Create a patient pipeline that contains the four pipelines and use a schedule trigger.
D. Create a patient pipeline that contains the four pipelines and use an event trigger.
-
Question 224:
You are planning a solution to aggregate streaming data that originates in Apache Kafka and is output to Azure Data Lake Storage Gen2. The developers who will implement the stream processing solution use Java. Which service should you recommend using to process the streaming data?
A. Azure Event Hubs
B. Azure Data Factory
C. Azure Stream Analytics
D. Azure Databricks
-
Question 225:
You are designing a financial transactions table in an Azure Synapse Analytics dedicated SQL pool. The table will have a clustered columnstore index and will include the following columns:
1.
TransactionType: 40 million rows per transaction type
2.
CustomerSegment: 4 million per customer segment
3.
TransactionMonth: 65 million rows per month
4.
AccountType: 500 million per account type
You have the following query requirements:
1.
Analysts will most commonly analyze transactions for a given month.
2.
Transactions analysis will typically summarize transactions by transaction type, customer segment, and/or account type
You need to recommend a partition strategy for the table to minimize query times.
On which column should you recommend partitioning the table?
A. CustomerSegment
B. AccountType
C. TransactionType
D. TransactionMonth
-
Question 226:
You are implementing a batch dataset in the Parquet format.
Data files will be produced be using Azure Data Factory and stored in Azure Data Lake Storage Gen2. The files will be consumed by an Azure Synapse Analytics serverless SQL pool.
You need to minimize storage costs for the solution.
What should you do?
A. Use Snappy compression for files.
B. Use OPENROWSET to query the Parquet files.
C. Create an external table that contains a subset of columns from the Parquet files.
D. Store all data as string in the Parquet files.
-
Question 227:
You are designing a data mart for the human resources (HR) department at your company. The data mart will contain employee information and employee transactions.
From a source system, you have a flat extract that has the following fields:
1.
EmployeeID
2.
FirstName
3.
LastName
4.
Recipient
5.
GrossAmount
6.
TransactionID
7.
GovernmentID
8.
NetAmountPaid
9.
TransactionDate
You need to design a star schema data model in an Azure Synapse Analytics dedicated SQL pool for the data mart.
Which two tables should you create? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. a dimension table for Transaction
B. a dimension table for EmployeeTransaction
C. a dimension table for Employee
D. a fact table for Employee
E. a fact table for Transaction
-
Question 228:
You have an Azure Synapse Analytics workspace named WS1 that contains an Apache Spark pool named Pool1.
You plan to create a database named DB1 in Pool1.
You need to ensure that when tables are created in DB1, the tables are available automatically as external tables to the built-in serverless SQL pool.
Which format should you use for the tables in DB1?
A. CSV
B. ORC
C. JSON
D. Parquet
-
Question 229:
You build a data warehouse in an Azure Synapse Analytics dedicated SQL pool.
Analysts write a complex SELECT query that contains multiple JOIN and CASE statements to transform data for use in inventory reports. The inventory reports will use the data and additional WHERE parameters depending on the report. The
reports will be produced once daily.
You need to implement a solution to make the dataset available for the reports. The solution must minimize query times.
What should you implement?
A. an ordered clustered columnstore index
B. a materialized view
C. result set caching
D. a replicated table
-
Question 230:
You are designing a slowly changing dimension (SCD) for supplier data in an Azure Synapse Analytics dedicated SQL pool.
You plan to keep a record of changes to the available fields.
The supplier data contains the following columns.
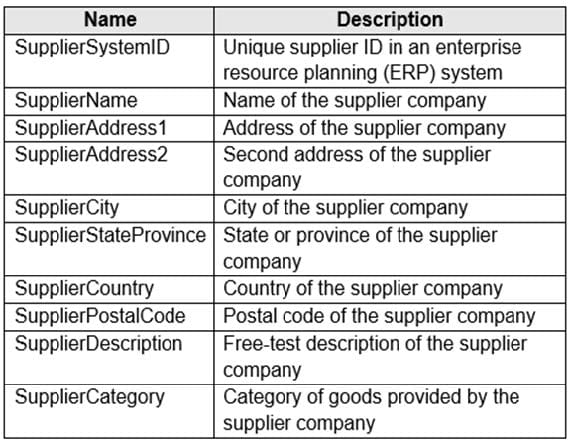
Which three additional columns should you add to the data to create a Type 2 SCD? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. surrogate primary key
B. effective start date
C. business key
D. last modified date
E. effective end date
F. foreign key
Related Exams:
62-193
Technology Literacy for Educators70-243
Administering and Deploying System Center 2012 Configuration Manager70-355
Universal Windows Platform – App Data, Services, and Coding Patterns77-420
Excel 201377-427
Excel 2013 Expert Part One77-725
Word 2016 Core Document Creation, Collaboration and Communication77-726
Word 2016 Expert Creating Documents for Effective Communication77-727
Excel 2016 Core Data Analysis, Manipulation, and Presentation77-728
Excel 2016 Expert: Interpreting Data for Insights77-731
Outlook 2016 Core Communication, Collaboration and Email Skills
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Microsoft exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DP-203 exam preparations and Microsoft certification application, do not hesitate to visit our Vcedump.com to find your solutions here.