Microsoft Microsoft Certifications DP-203 Questions & Answers
Question 51:
You have an Azure SQL database named DB1 and an Azure Data Factory data pipeline named pipeline.
From Data Factory, you configure a linked service to DB1.
In DB1, you create a stored procedure named SP1. SP1 returns a single row of data that has four columns.
You need to add an activity to pipeline to execute SP1. The solution must ensure that the values in the columns are stored as pipeline variables.
Which two types of activities can you use to execute SP1? (Refer to Data Engineering on Microsoft Azure documents or guide for Answers/available at Microsoft.com)
A. Script
B. Copy
C. Lookup
D. Stored Procedure
Correct Answer: AD
A: You use data transformation activities in a Data Factory or Synapse pipeline to transform and process raw data into predictions and insights. The Script activity is one of the transformation activities that pipelines support.
You can use the Script activity to invoke a SQL script in one of the following data stores in your enterprise or on an Azure virtual machine (VM):
The script may contain either a single SQL statement or multiple SQL statements that run sequentially. You can use the Script task for the following purposes:
Truncate a table in preparation for inserting data.
Create, alter, and drop database objects such as tables and views.
Re-create fact and dimension tables before loading data into them.
*-> Run stored procedures. If the SQL statement invokes a stored procedure that returns results from a temporary table, use the WITH RESULT SETS option to define metadata for the result set.
Save the rowset returned from a query as activity output for downstream consumption.
D: You can transform data by using the SQL Server Stored Procedure activity in Azure Data Factory or Synapse Analytics.
You use data transformation activities in a Data Factory or Synapse pipeline to transform and process raw data into predictions and insights. The Stored Procedure Activity is one of the transformation activities that pipelines support.
You can use the Stored Procedure Activity to invoke a stored procedure in one of the following data stores in your enterprise or on an Azure virtual machine (VM):
Azure SQL Database Azure Synapse Analytics SQL Server Database.
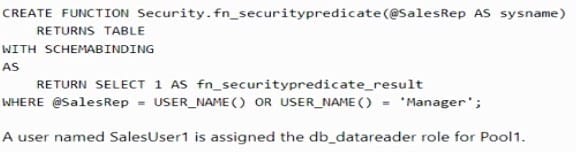
You have an Azure Synapse Analytics dedicated SQL pool named Pool1 that contains a table named Sales. Sales has row-level security (RLS) applied. RLS uses the following predicate filter.
A user named SalesUser1 is assigned the db_datareader role for Pool1. Which rows in the Sales table are returned when SalesUser1 queries the table?
A. only the rows for which the value in the User_Name column is SalesUser1
B. all the rows
C. only the rows for which the value in the SalesRep column is Manager
D. only the rows for which the value in the SalesRep column is SalesUser1
Correct Answer: D
Create a new schema, and an inline table-valued function. The function returns 1 when a row in the SalesRep column is the same as the user executing the query (@SalesRep = USER_NAME()) or if the user executing the query is the Manager user (USER_NAME() = 'Manager'). This example of a user-defined, table-valued function is useful to serve as a filter for the security policy created in the next step.
CREATE SCHEMA Security; GO
CREATE FUNCTION Security.tvf_securitypredicate(@SalesRep AS nvarchar(50))
RETURNS TABLE WITH SCHEMABINDING AS
RETURN SELECT 1 AS tvf_securitypredicate_result WHERE @SalesRep = USER_NAME() OR USER_NAME() = 'Manager';
Note:
Now test the filtering predicate, by selected from the Sales.Orders table as each user.
EXECUTE AS USER = 'SalesRep1';
SELECT * FROM Sales.Orders;
REVERT;
EXECUTE AS USER = 'SalesRep2';
SELECT * FROM Sales.Orders;
REVERT;
EXECUTE AS USER = 'Manager'; SELECT * FROM Sales.Orders; REVERT;
The manager should see all six rows. The Sales1 and Sales2 users should only see their own sales.
You have an Azure Synapse Analytics dedicated SQL pool that contains a table named Table1. Table1 contains the following:
1.
One billion rows
2.
A clustered columnstore index
3.
A hash-distributed column named Product Key
4.
A column named Sales Date that is of the date data type and cannot be null
Thirty million rows will be added to Table1 each month.
You need to partition Table1 based on the Sales Date column. The solution must optimize query performance and data loading. How often should you create a partition?
A. once per month
B. once per year
C. once per day
D. once per week
Correct Answer: B
Need a minimum 1 million rows per distribution. Each table is 60 distributions. 30 millions rows is added each month. Need 2 months to get a minimum of 1 million rows per distribution in a new partition.
Note: When creating partitions on clustered columnstore tables, it is important to consider how many rows belong to each partition. For optimal compression and performance of clustered columnstore tables, a minimum of 1 million rows per
distribution and partition is needed. Before partitions are created, dedicated SQL pool already divides each table into 60 distributions.
Any partitioning added to a table is in addition to the distributions created behind the scenes. Using this example, if the sales fact table contained 36 monthly partitions, and given that a dedicated SQL pool has 60 distributions, then the sales
fact table should contain 60 million rows per month, or 2.1 billion rows when all months are populated. If a table contains fewer than the recommended minimum number of rows per partition, consider using fewer partitions in order to increase
You have an Azure Databricks workspace that contains a Delta Lake dimension table named Table1.
Table1 is a Type 2 slowly changing dimension (SCD) table.
You need to apply updates from a source table to Table1.
Which Apache Spark SQL operation should you use?
A. CREATE
B. UPDATE
C. MERGE
D. ALTER
Correct Answer: C
The Delta provides the ability to infer the schema for data input which further reduces the effort required in managing the schema changes. The Slowly Changing Data(SCD) Type 2 records all the changes made to each key in the dimensional
table. These operations require updating the existing rows to mark the previous values of the keys as old and then inserting new rows as the latest values. Also, Given a source table with the updates and the target table with dimensional data,
SCD Type 2 can be expressed with the merge.
Example:
// Implementing SCD Type 2 operation using merge function customersTable as("customers")
merge(
stagedUpdates.as("staged_updates"),
"customers.customerId = mergeKey")
whenMatched("customers.current = true AND customers.address <> staged_updates.address") updateExpr(Map(
You have an Azure Data Factory pipeline named Pipeline1!. Pipelinel contains a copy activity that sends data to an Azure Data Lake Storage Gen2 account. Pipeline 1 is executed by a schedule trigger.
You change the copy activity sink to a new storage account and merge the changes into the collaboration branch.
After Pipelinel executes, you discover that data is NOT copied to the new storage account.
You need to ensure that the data is copied to the new storage account.
What should you do?
A. Publish from the collaboration branch.
B. Configure the change feed of the new storage account.
C. Create a pull request.
D. Modify the schedule trigger.
Correct Answer: A
CI/CD lifecycle
1.
A development data factory is created and configured with Azure Repos Git. All developers should have permission to author Data Factory resources like pipelines and datasets.
2.
A developer creates a feature branch to make a change. They debug their pipeline runs with their most recent changes
3.
After a developer is satisfied with their changes, they create a pull request from their feature branch to the main or collaboration branch to get their changes reviewed by peers.
4.
After a pull request is approved and changes are merged in the main branch, the changes get published to the development factory.
What should you recommend to prevent users outside the Litware on-premises network from accessing the analytical data store?
A. a server-level virtual network rule
B. a database-level virtual network rule
C. a server-level firewall IP rule
D. a database-level firewall IP rule
Correct Answer: C
Scenario:
1.
Ensure that the analytical data store is accessible only to the company's on-premises network and Azure services.
2.
Litware does not plan to implement Azure ExpressRoute or a VPN between the on-premises network and Azure.
Since Litware does not plan to implement Azure ExpressRoute or a VPN between the on-premises network and Azure, they will have to create firewall IP rules to allow connection from the IP ranges of the on-premise network. They can also use the firewall rule 0.0.0.0 to allow access from Azure services.
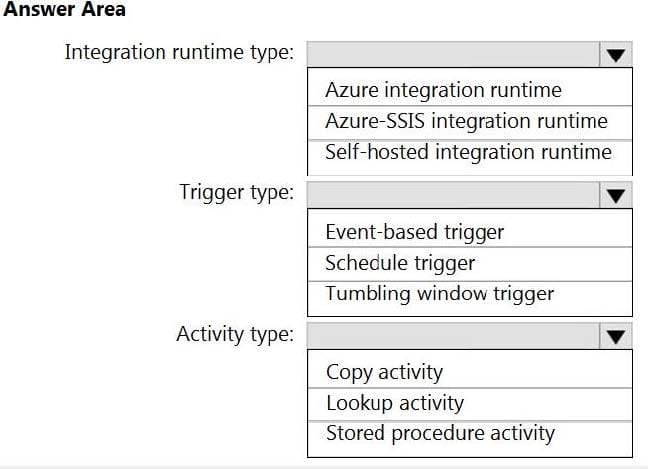
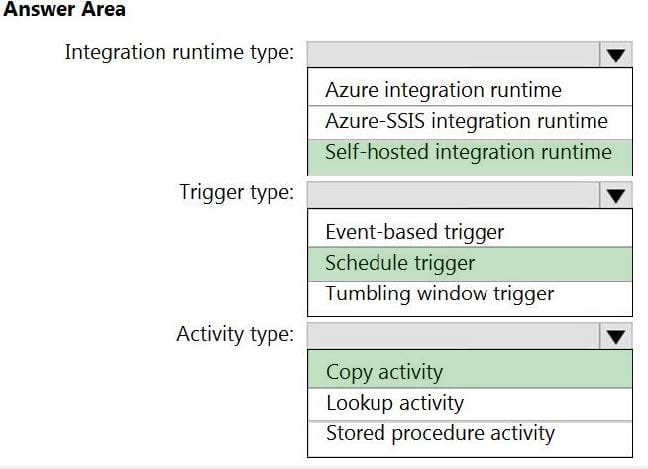
Which Azure Data Factory components should you recommend using together to import the daily inventory data from the SQL server to Azure Data Lake Storage? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:
Box 1: Self-hosted integration runtime
A self-hosted IR is capable of running copy activity between a cloud data stores and a data store in private network.
Box 2: Schedule trigger
Schedule every 8 hours
Box 3: Copy activity
Scenario:
Customer data, including name, contact information, and loyalty number, comes from Salesforce and can be imported into Azure once every eight hours. Row modified dates are not trusted in the source table.
Product data, including product ID, name, and category, comes from Salesforce and can be imported into Azure once every eight hours. Row modified dates are not trusted in the source table.
Question 58:
HOTSPOT
You need to design the partitions for the product sales transactions. The solution must meet the sales transaction dataset requirements.
What should you include in the solution? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:
Box 1: Sales date
Scenario: Contoso requirements for data integration include:
Partition data that contains sales transaction records. Partitions must be designed to provide efficient loads by month. Boundary values must belong to the partition on the right.
Box 2: An Azure Synapse Analytics Dedicated SQL pool
Scenario: Contoso requirements for data integration include:
Ensure that data storage costs and performance are predictable.
The size of a dedicated SQL pool (formerly SQL DW) is determined by Data Warehousing Units (DWU).
Dedicated SQL pool (formerly SQL DW) stores data in relational tables with columnar storage. This format significantly reduces the data storage costs, and improves query performance.
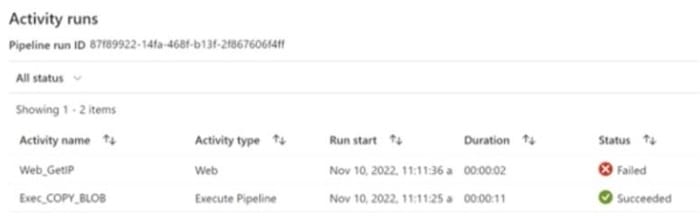
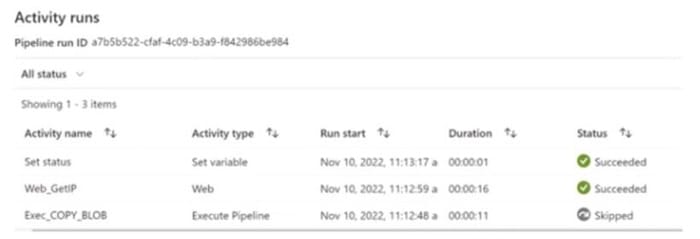
You have an Azure Data Factory pipeline shown the following exhibit.
The execution log for the first pipeline run is shown in the following exhibit.
The execution log for the second pipeline run is shown in the following exhibit.
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:
Question 60:
HOTSPOT
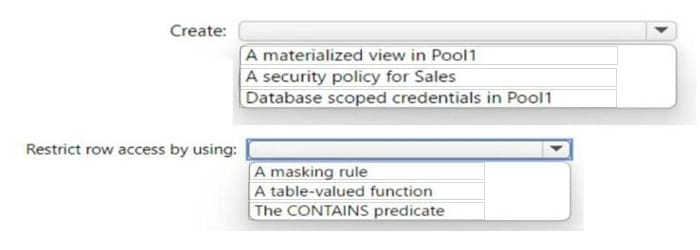
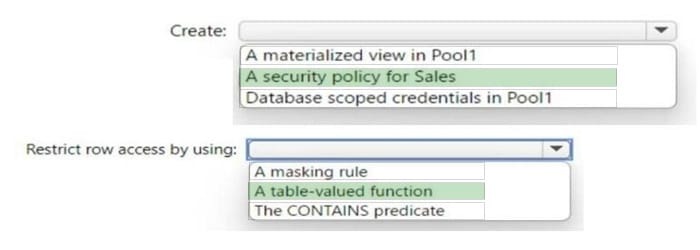
You have an Azure Synapse Analytics dedicated SQL pool named Pool1 that contains an external table named Sales. Sales contains sales data. Each row in Sales contains data on a single sale, including the name of the salesperson.
You need to implement row-level security (RLS). The solution must ensure that the salespeople can access only their respective sales.
What should you do? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:
Box 1: A security policy for sale
Here are the steps to create a security policy for Sales:
Create a user-defined function that returns the name of the current user:
CREATE FUNCTION dbo.GetCurrentUser()
RETURNS NVARCHAR(128)
AS
BEGIN
RETURN SUSER_SNAME();
END;
Create a security predicate function that filters the Sales table based on the
current user:
CREATE FUNCTION dbo.SalesPredicate(@salesperson NVARCHAR(128)) RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN SELECT 1 AS access_result
WHERE @salesperson = SalespersonName;
Create a security policy on the Sales table that uses the SalesPredicate function to filter the data:
CREATE SECURITY POLICY SalesFilter
ADD FILTER PREDICATE dbo.SalesPredicate(dbo.GetCurrentUser()) ON dbo.Sales
WITH (STATE = ON);
By creating a security policy for the Sales table, you ensure that each salesperson can only access their own sales data. The security policy uses a user-defined function to get the name of the current user and a security predicate function to
filter the Sales table based on the current user.
Box 2: table-value function
to restrict row access by using row-level security, you need to create a table-valued function that returns a table of values that represent the rows that a user can access. You then use this function in a security policy that applies a predicate on
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Microsoft exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DP-203 exam preparations and Microsoft certification application, do not hesitate to visit our Vcedump.com to find your solutions here.