Exam Details
Exam Code
:DP-203Exam Name
:Data Engineering on Microsoft AzureCertification
:Microsoft CertificationsVendor
:MicrosoftTotal Questions
:414 Q&AsLast Updated
:Jul 07, 2025
Microsoft Microsoft Certifications DP-203 Questions & Answers
-
Question 61:
HOTSPOT
You have two Azure SQL databases named DB1 and DB2.
DB1 contains a table named Table 1. Table1 contains a timestamp column named LastModifiedOn. LastModifiedOn contains the timestamp of the most recent update for each individual row.
DB2 contains a table named Watermark. Watermark contains a single timestamp column named WatermarkValue.
You plan to create an Azure Data Factory pipeline that will incrementally upload into Azure Blob Storage all the rows in Table1 for which the LastModifiedOn column contains a timestamp newer than the most recent value of the
WatermarkValue column in Watermark.
You need to identify which activities to include in the pipeline. The solution must meet the following requirements:
Minimize the effort to author the pipeline.
Ensure that the number of data integration units allocated to the upload operation can be controlled.
What should you identify? To answer, select the appropriate options in the answer area.
Hot Area:
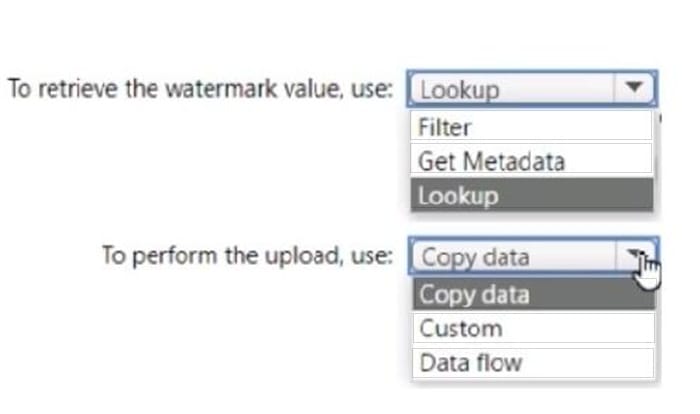
-
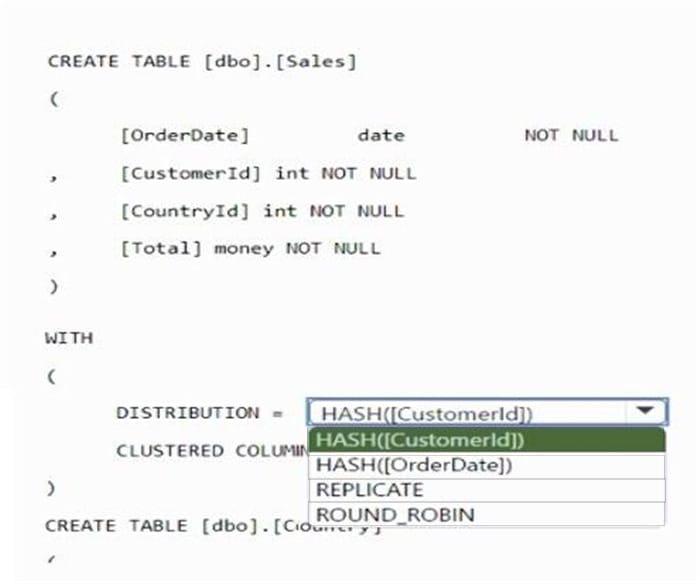
Question 62:
HOTSPOT
You have an Azure subscription that contains an Azure Synapse Analytics dedicated SQL pool. You plan to deploy a solution that will analyze sales data and include the following:
A table named Country that will contain 195 rows
A table named Sales that will contain 100 million rows
A query to identify total sales by country and customer from the past 30 days
You need to create the tables. The solution must maximize query performance.
How should you complete the script? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
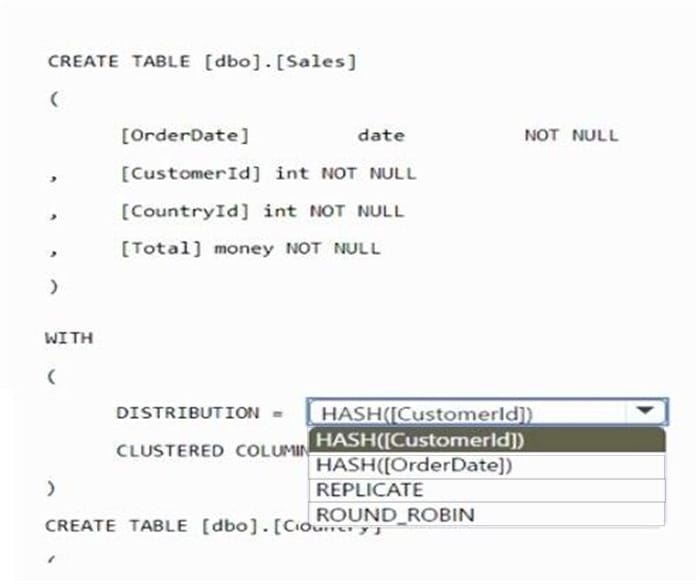
-
Question 63:
HOTSPOT
You have an Azure Data Factory pipeline that contains a data flow. The data flow contains the following expression.

Hot Area:
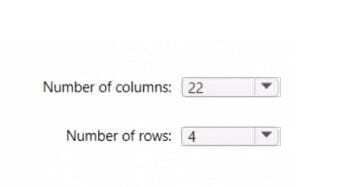
-
Question 64:
HOTSPOT
You have an Azure Synapse Analytics serverless SQL pool, an Azure Synapse Analytics dedicated SQL pool, an Apache Spark pool, and an Azure Data Lake Storage Gen2 account.
You need to create a table in a lake database. The table must be available to both the serverless SQL pool and the Spark pool.
Where should you create the table, and Which file format should you use for data in the table? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
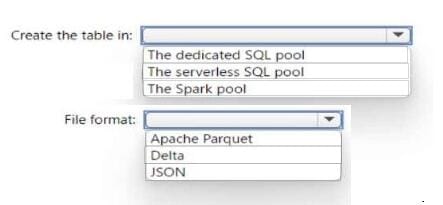
-
Question 65:
HOTSPOT
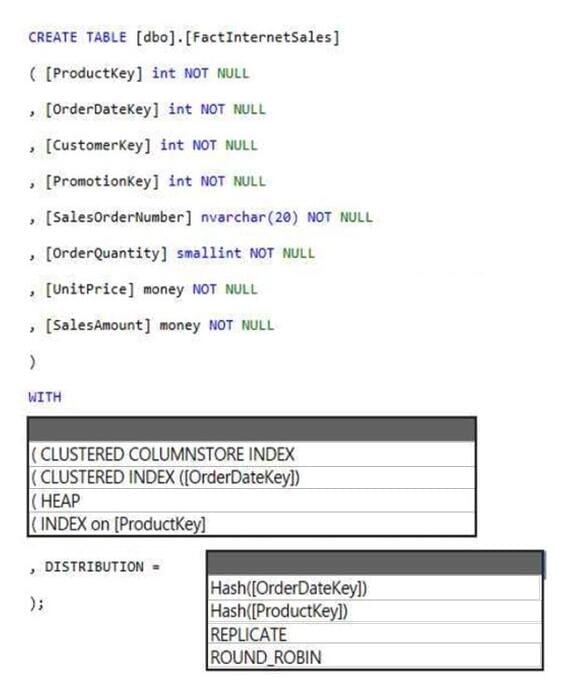
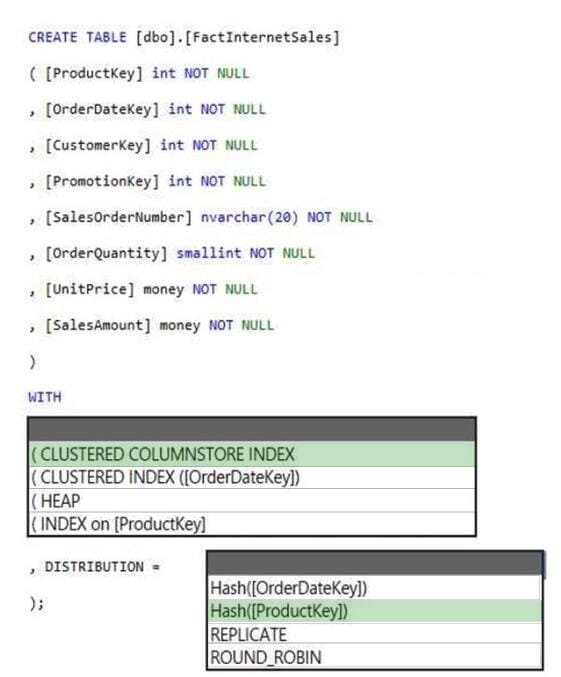
You have an Azure Synapse Analytics dedicated SQL pool.
You need to create a table named FactInternetSales that will be a large fact table in a dimensional model. FactInternetSales will contain 100 million rows and two columns named SalesAmount and OrderQuantity. Queries executed on
FactInternetSales will aggregate the values in SalesAmount and OrderQuantity from the last year for a specific product. The solution must minimize the data size and query execution time.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
-
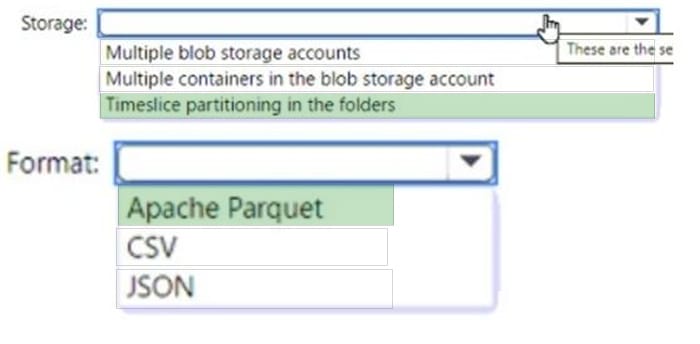
Question 66:
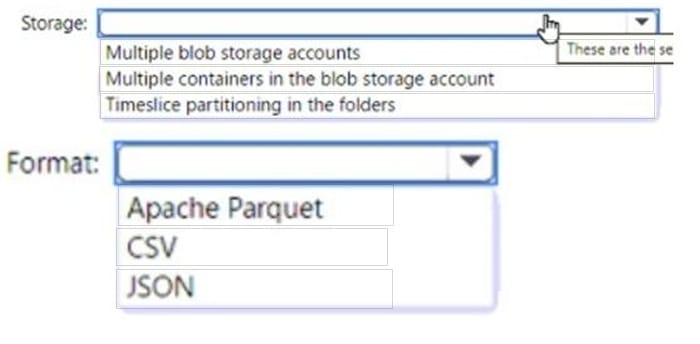
HOTSPOT
You have an Azure Blob storage account that contains a folder. The folder contains 120,000 files. Each file contains 62 columns.
Each day, 1,500 new files are added to the folder.
You plan to incrementally load five data columns from each new file into an Azure Synapse Analytics workspace.
You need to minimize how long it takes to perform the incremental loads.
What should you use to store the files and format?
Hot Area:
-
Question 67:
HOTSPOT
You have an Azure Synapse Analytics pipeline named Pipeline1 that contains a data flow activity named Dataflow1.
Pipeline1 retrieves files from an Azure Data Lake Storage Gen 2 account named storage1.
Dataflow1 uses the AutoResolveIntegrationRuntime integration runtime configured with a core count of 128. You need to optimize the number of cores used by Dataflow1 to accommodate the size of the files in storage1. What should you configure? To answer, select the appropriate options in the answer area.
Hot Area:

-
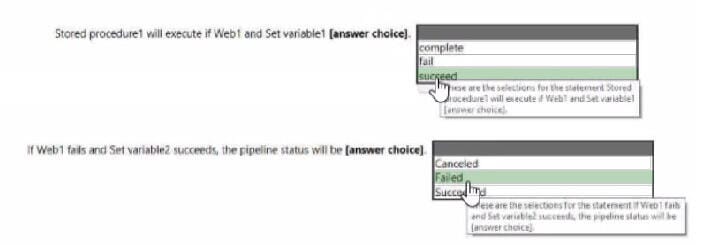
Question 68:
HOTSPOT
You have an Azure Data Factory pipeline that has the activity shown in the following exhibit.
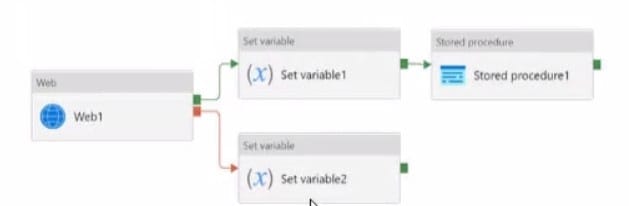
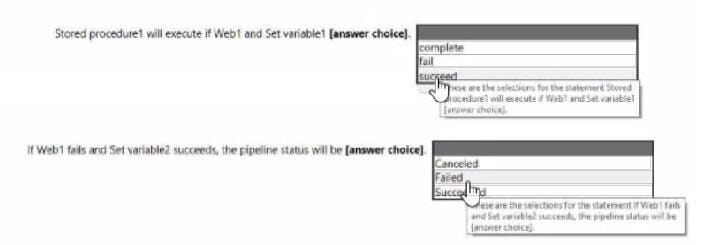
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic.
Hot Area:
-
Question 69:
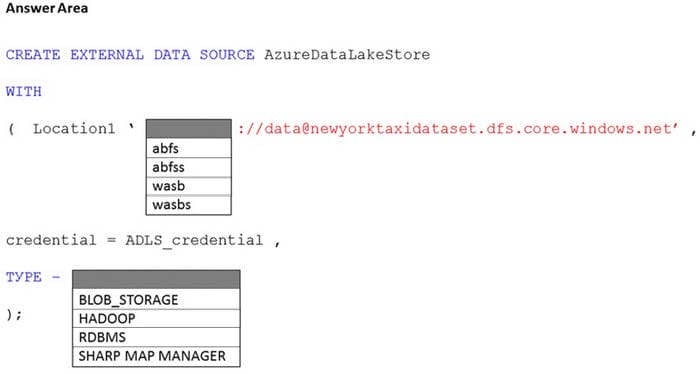
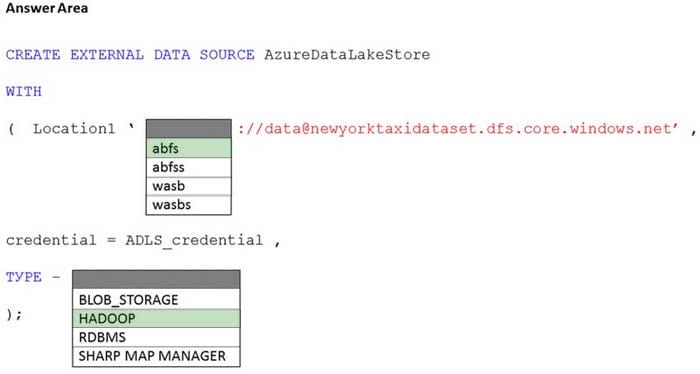
HOTSPOT
You have an Azure subscription that contains an Azure Synapse Analytics dedicated SQL pool named Pool1 and an Azure Data Lake Storage account named storage1. Storage1 requires secure transfers.
You need to create an external data source in Pool1 that will be used to read .orc files in storage1.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
-
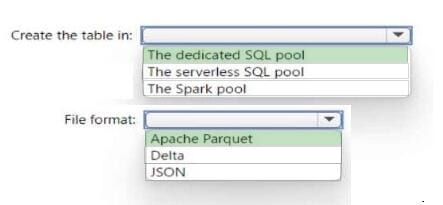
Question 70:
HOTSPOT
You are building a database in an Azure Synapse Analytics serverless SQL pool.
You have data stored in Parquet files in an Azure Data Lake Storege Gen2 container.
Records are structured as shown in the following sample.
{
"id": 123,
"address_housenumber": "19c",
"address_line": "Memory Lane",
"applicant1_name": "Jane",
"applicant2_name": "Dev"
}
The records contain two applicants at most.
You need to build a table that includes only the address fields.
How should you complete the Transact-SQL statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:




Related Exams:
62-193
Technology Literacy for Educators70-243
Administering and Deploying System Center 2012 Configuration Manager70-355
Universal Windows Platform – App Data, Services, and Coding Patterns77-420
Excel 201377-427
Excel 2013 Expert Part One77-725
Word 2016 Core Document Creation, Collaboration and Communication77-726
Word 2016 Expert Creating Documents for Effective Communication77-727
Excel 2016 Core Data Analysis, Manipulation, and Presentation77-728
Excel 2016 Expert: Interpreting Data for Insights77-731
Outlook 2016 Core Communication, Collaboration and Email Skills
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Microsoft exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DP-203 exam preparations and Microsoft certification application, do not hesitate to visit our Vcedump.com to find your solutions here.